![[Hive] Metastore의 heap memory 증가 이슈 해결 과정](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbrtPDh%2FbtrHAGLLdUx%2FjTglQhaGqHKNivz1CJfhTK%2Fimg.png)
이번 글에서는 토이 프로젝트를 진행하면서 Hive Metastore의 heap memory가 비정상적으로 증가하는 이슈의 해결 과정에 대해 공유하겠습니다. 해당 이슈 해결 과정을 보기에 앞서 [Hive] Hive 아키텍처와 HiveServer2 & Hive Metastore 글을 읽으면 좀 더 이해하기 쉬울 것이라고 생각됩니다.
문제 발견
Hive를 사용하면서 Hive 쿼리가 정상적으로 수행되지 않는 문제를 발견하게 되었습니다. 처음에는 Hiveserver2가 다운된 문제라고 생각했습니다. 하지만 이상한 점은 Hiveserver2 프로세스가 죽지 않고 살아있었다는 점입니다. 어쨌든 문제의 원인을 파악하기 위해 Hiveserver2의 로그를 분석했습니다.
로그 분석
| hiveserver2.log |
| WARN [PrivilegeSynchonizer]: megastore.RetryingMetaStoreClient (:()) - MetaStoreClient lost connection. Attempting to reconnect (20 of 24) after 5s. refresh_privileges org.apache.thrift.transport.TTransprotException: null at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java) …. at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_refresh_privileges(ThriftHiveMetastore.java) at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.refresh_privileges(ThriftHiveMetastore.java) at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.refresh_privileges(HiveMetaStoreClient.java) …. at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetastoreClient.java) |
hiveserver2.log에 정말 다양한 로그들이 적혀있었고 그중에 대표적으로 위의 내용만 적었다는 점 참고 바랍니다. 위의 내용을 봤을 때, 로그가 찍히고 있던 상태이므로 Hiveserver2는 살아있지만 Metastore와의 통신이 정상적으로 이루어지지 않는다는 것을 알게되었습니다. 그래서 다시 hivemetastore.log 를 분석했습니다.
| hivemetastore.log |
| ERROR [pool-6thread-196] : server.TThreadPoolServer (TThreadPoolServer.java:run(297)) - Error occurred during processing of message. java.lang.RuntimeException: javax.jdo.JDOException: Exception thrown when executing query : SELECT DISTINCT ‘org.apache.hadoop.hive.metastore.model.MTableColumnPrivilege’ AS ’NUCLEUS_TYPE’, ‘A0’. ‘AUTHORIZER’, ‘A0’. ……. NestedThrowables: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure The last packet successfully received from the server was 361,352 milliseconds ago. The last packet sent successfully to the server was 361,352 milliseconds ago. at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.refresh_privileges(HiveMetaStore.java) …. at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Processor$refresh_privileges.getResult(ThriftHiveMetastore.hava) …. |
| ERROR [pool-6-thread-6] : metastore.RetryingHMSHandler (RetryingHMSHandler.java:invokeInternal(201)) - java.lang.OutOfMemoryError: Java heap space |
마찬가지로 hivemetastore.log의 경우에도 다양하게 원인을 알 수 있을 여러가지 로그들이 많았지만, 위의 에러 2개만 대표로 적었습니다. 위의 로그들을 봤을 때, Hiveserver2와 Metastore는 privilege 관련된 작업을 진행하면서 RDB를 사용하고 그로 인해 Java heap memory가 부족해지는 현상이라는 것을 파악하게 되었습니다.
Grafana로 Metastore 분석
Metastore의 heap memory가 부족하다는 것을 파악한 뒤, Grafana를 이용해 메모리 사용량을 확인했습니다. 그 결과 아래의 그래프처럼 Metastore의 heap 사용량이 짧은 시간에 상당히 증가하는 것을 확인할 수 있었습니다. 그리고 추가적으로 Metastore의 GC의 정보도 살펴봤습니다. Young GC, Old GC 모두 확인을 했지만, 아래 그래프에서는 Old GC만 표현했습니다.
( 아래 그림은 Grafana 그래프를 요약한 내용입니다. )

위의 그래프를 참고로 Metastore의 문제를 분석해보면 다음과 같았습니다.
1. Metastore는 짧은 시간에 heap memory가 빠르게 증가한다.
2. Heap memory가 full이 되면 이후로 Metastore가 동작하지 않아 그래프에 데이터가 기록되지 않는다.
3. Metastore가 멈출 때는 Old GC가 기록된다.
- 결국 Metastore의 heap memory가 빠르게 증가해 full이 되면, Old GC 발생으로 Metastore가 동작 X
위의 그래프를 통해 Metastore Heap memory의 빠른 증가가 문제의 원인이라는 것을 파악할 수 있었습니다.
Heap dump 분석
Metastore의 heap memory가 비정상적으로 증가하는 이유에 대해서 분석하고자 했습니다. Metastore의 heap memory 이슈 관련해서 검색을 했을 때는 대부분 heap size를 늘리라는 내용밖에 찾지 못했습니다. (일반적인 connection이 많은 경우의 운영 클러스터도 보통 20GB 미만으로 설정 ) 하지만 저의 경우 테스트를 위해서 약 80GB까지도 heap size를 늘려봤지만 heap memory가 full이 되는 것은 막을 수가 없었습니다. 그래서 도대체 이렇게 거대한 양의 메모리를 잡아먹고 있는 범인이 누구인지 알기 위해 heap dump를 생성했습니다.
사실 heap memory가 full이 되었을 때 dump를 생성해 분석하고 싶었지만, dump 파일 자체의 크기가 수십 GB가 되어 분석 툴에 올릴 수가 없었습니다. 그래서 Hive를 재시작 후 heap memory가 증가하기 시작할 때쯤 dump를 생성해 약 4~5GB에서 분석을 진행했습니다. Java heap memory 분석은 아래 툴을 이용했습니다.
Eclipse Memory Analyzer Open Source Project | The Eclipse Foundation
The Eclipse Foundation - home to a global community, the Eclipse IDE, Jakarta EE and over 415 open source projects, including runtimes, tools and frameworks.
www.eclipse.org
heap dump를 MAT에 올려 분석을 했을 때 아래와 같은 결과가 나왔습니다. ( 필요한 내용만 요약해서 표현했습니다. )
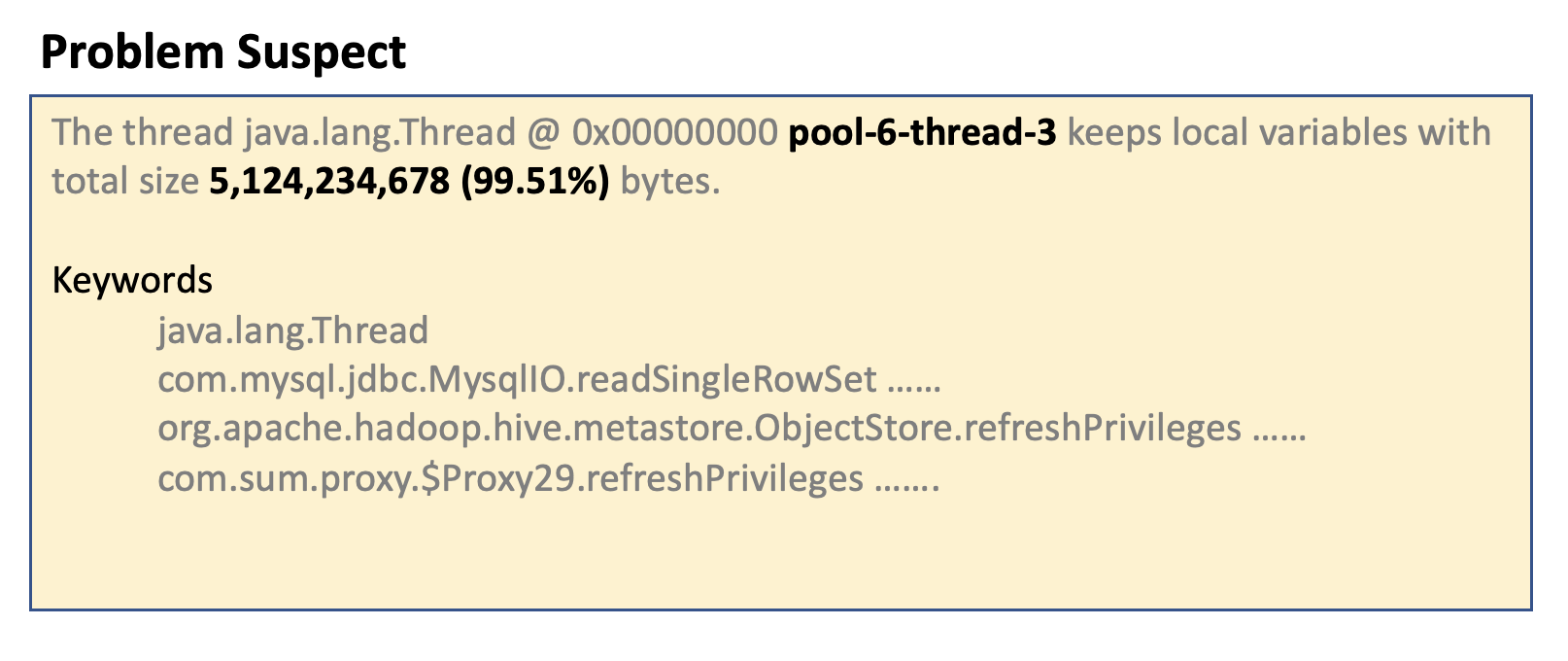
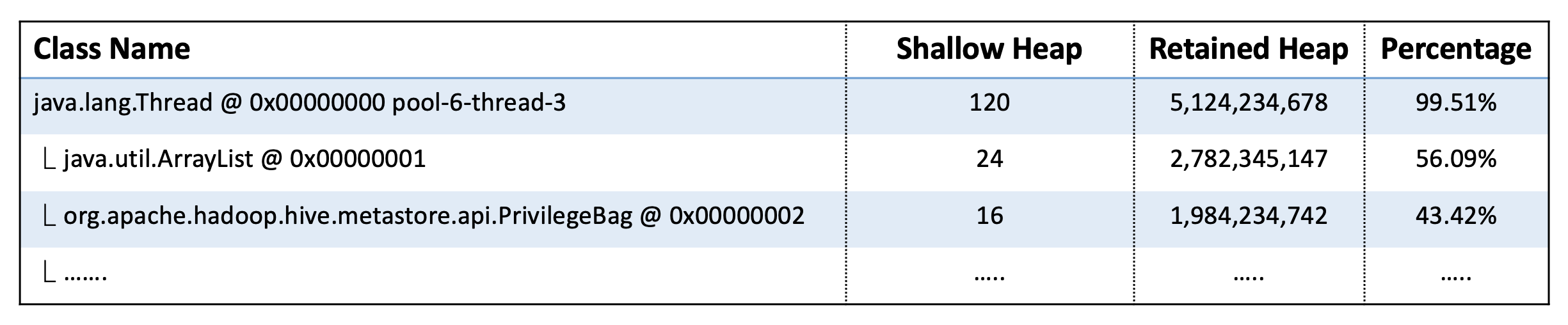
결과를 분석하면 아래와 같습니다.
- 특정 thread 하나가 Metastore heap memory 거의 대부분을 차지한다.
- 문제의 thread memory는 ArrayList와 PrivilegeBag 객체로 이루어져 있다.
( ArrayList가 PrivilegeBag을 포함하기 때문에 결국에는 같은 객체로 봐야 함 )
- Privilege 관련 객체가 문제의 원인이다.
위의 Hiveserver2와 Metastore의 로그에서도 확인할 수 있었던 Privilege 관련 내용이 heap memory에서도 발견되었습니다. 이것은 결국 Hive가 DB 및 Table을 사용하는데 필요한 Privilege를 관리하는 과정에서 문제가 있다는 것을 알 수 있었습니다.
Hive source code 분석
MAT을 통해 문제 Thread의 Stack trace를 볼 수 있었고 PrivilegeBag 객체가 어떻게 사용되는지를 알 수 있었습니다.
| Thread Stack trace |
| Pool-6-thread-3 at java.net.SocketInputStream.socketRead0(Ljava/io/FileDescriptor;) …. at com.mysql.jdbc.util.ReadAheadInputStream.fill(l)V (ReadAheadInputStream.java) …. at org.apache.hadoop.hive.metastore.ObjectStore.listTableAllColumnGrants()Java/util/List; (ObjectStore.java) at org.apache.hadoop.hive.metastore.ObjectStore.refreshPrivileges()Z (ObjectStore.java) …. at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.refresh_privileges() (HiveMetaStore.java) …. at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Processor$refresh_privileges.getResult() (ThriftHiveMetastore.java) …. |
Stack trace에 기록된 Hive source code를 보면 Privilege를 refresh 하는 과정에서 모든 column의 privilege 정보를 PrivilegeBag 객체에 담고 최종적으로 ArrayList 형태로 존재한다는 것을 알 수 있었습니다. 아래 코드는 Hive Github에서 볼 수 있습니다.
ObjectStore.java - refreshPrivileges() (Link)
@Override
public boolean refreshPrivileges(HiveObjectRef objToRefresh, String authorizer, PrivilegeBag grantPrivileges)
throws InvalidObjectException, MetaException, NoSuchObjectException {
boolean committed = false;
try {
openTransaction();
Set<HiveObjectPrivilege> revokePrivilegeSet
= new TreeSet<>(new PrivilegeWithoutCreateTimeComparator());
Set<HiveObjectPrivilege> grantPrivilegeSet
= new TreeSet<>(new PrivilegeWithoutCreateTimeComparator());
List<HiveObjectPrivilege> grants = null;
String catName = objToRefresh.isSetCatName() ? objToRefresh.getCatName() :
getDefaultCatalog(conf);
switch (objToRefresh.getObjectType()) {
case DATABASE:
try {
grants = this.listDBGrantsAll(catName, objToRefresh.getDbName(), authorizer);
} catch (Exception e) {
throw new MetaException(e.getMessage());
}
break;
case DATACONNECTOR:
try {
grants = this.listDCGrantsAll(objToRefresh.getObjectName(), authorizer);
} catch (Exception e) {
throw new MetaException(e.getMessage());
}
break;
case TABLE:
grants = listTableGrantsAll(catName, objToRefresh.getDbName(), objToRefresh.getObjectName(), authorizer);
break;
case COLUMN:
Preconditions.checkArgument(objToRefresh.getColumnName()==null, "columnName must be null");
grants = getTableAllColumnGrants(catName, objToRefresh.getDbName(),
objToRefresh.getObjectName(), authorizer);
break;
default:
throw new MetaException("Unexpected object type " + objToRefresh.getObjectType());
}
revokePrivilegeSet.addAll(grants);
// Optimize revoke/grant list, remove the overlapping
if (grantPrivileges.getPrivileges() != null) {
for (HiveObjectPrivilege grantPrivilege : grantPrivileges.getPrivileges()) {
if (revokePrivilegeSet.contains(grantPrivilege)) {
revokePrivilegeSet.remove(grantPrivilege);
} else {
grantPrivilegeSet.add(grantPrivilege);
}
}
}
if (!revokePrivilegeSet.isEmpty()) {
LOG.debug("Found " + revokePrivilegeSet.size() + " new revoke privileges to be synced.");
PrivilegeBag remainingRevokePrivileges = new PrivilegeBag();
for (HiveObjectPrivilege revokePrivilege : revokePrivilegeSet) {
remainingRevokePrivileges.addToPrivileges(revokePrivilege);
}
revokePrivileges(remainingRevokePrivileges, false);
} else {
LOG.debug("No new revoke privileges are required to be synced.");
}
if (!grantPrivilegeSet.isEmpty()) {
LOG.debug("Found " + grantPrivilegeSet.size() + " new grant privileges to be synced.");
PrivilegeBag remainingGrantPrivileges = new PrivilegeBag();
for (HiveObjectPrivilege grantPrivilege : grantPrivilegeSet) {
remainingGrantPrivileges.addToPrivileges(grantPrivilege);
}
grantPrivileges(remainingGrantPrivileges);
} else {
LOG.debug("No new grant privileges are required to be synced.");
}
committed = commitTransaction();
} finally {
if (!committed) {
rollbackTransaction();
}
}
return committed;
}
위의 코드에서 33~36번째 줄을 보시면 대략적으로 특정 테이블의 모든 column privilege을 불러온다는 것을 알 수 있습니다.
case COLUMN:
Preconditions.checkArgument(objToRefresh.getColumnName()==null, "columnName must be null");
grants = getTableAllColumnGrants(catName, objToRefresh.getDbName(),
objToRefresh.getObjectName(), authorizer);
여기에 명시된 getTableAllColumnGrants() 메소드는 결국 위의 Stack trace에 명시된 listTableAllColumnGrants() 메소드로 이어지고 아래의 내용처럼 RDB에 직접 쿼리를 수행하는 내용입니다. 즉 특정 테이블의 모든 column privilege를 RDB로부터 가져온다는 것을 알 수 있습니다.
ObjectStore.java - listTableAllColumnGrants() (Link)
private List<MTableColumnPrivilege> listTableAllColumnGrants(
String catName, String dbName, String tableName, String authorizer) {
boolean success = false;
Query query = null;
List<MTableColumnPrivilege> mTblColPrivilegeList = new ArrayList<>();
tableName = normalizeIdentifier(tableName);
dbName = normalizeIdentifier(dbName);
catName = normalizeIdentifier(catName);
try {
LOG.debug("Executing listTableAllColumnGrants");
openTransaction();
List<MTableColumnPrivilege> mPrivs = null;
if (authorizer != null) {
String queryStr = "table.tableName == t1 && table.database.name == t2 &&" +
"table.database.catalogName == t3 && authorizer == t4";
query = pm.newQuery(MTableColumnPrivilege.class, queryStr);
query.declareParameters("java.lang.String t1, java.lang.String t2, java.lang.String t3, " +
"java.lang.String t4");
mPrivs = (List<MTableColumnPrivilege>) query.executeWithArray(tableName, dbName, catName, authorizer);
} else {
String queryStr = "table.tableName == t1 && table.database.name == t2 &&" +
"table.database.catalogName == t3";
query = pm.newQuery(MTableColumnPrivilege.class, queryStr);
query.declareParameters("java.lang.String t1, java.lang.String t2, java.lang.String t3");
mPrivs = (List<MTableColumnPrivilege>) query.executeWithArray(tableName, dbName, catName);
}
LOG.debug("Query to obtain objects for listTableAllColumnGrants finished");
pm.retrieveAll(mPrivs);
LOG.debug("RetrieveAll on all the objects for listTableAllColumnGrants finished");
success = commitTransaction();
LOG.debug("Transaction running query to obtain objects for listTableAllColumnGrants " +
"committed");
mTblColPrivilegeList.addAll(mPrivs);
LOG.debug("Done retrieving " + mPrivs.size() + " objects for listTableAllColumnGrants");
} finally {
rollbackAndCleanup(success, query);
}
return mTblColPrivilegeList;
}
다음으로 알아야 했던 점은 refresh privilege가 왜 호출되는 것인가? 였습니다. ( 이 물음에 대한 답은 "결론"의 두번째 항목에 있습니다. ) 그래서 분석 툴을 통해 알 수 있었던 thread와 Metastore의 로그를 분석했습니다.
Metastore + heap dump 분석
Metastore 로그에서는 특정 thread의 이름과 어떤 작업을 수행했는지 명시되어 있습니다. 그래서 위의 MAT 분석 툴에서 명시된 pool-6-thread-3을 Metastore 로그에서 heap dump를 생성했던 시간대에서 찾아봤습니다. Metastore에서 찾을 수 있었던 내용은 아래와 같았습니다.
| hivemetastore.log |
| INFO [pool-6-thread-3]: cmd=source:xxx.xxx.xxx.xxx get_all_tables : db=@hive#example_db INFO [pool-6-thread-3]: cmd=source:xxx.xxx.xxx.xxx get_table : tbl=hive.example_db.example_table1 INFO [pool-6-thread-3]: cmd=source:xxx.xxx.xxx.xxx get_table : tbl=hive.example_db.example_table2 INFO [pool-6-thread-3]: cmd=source:xxx.xxx.xxx.xxx get_table : tbl=hive.example_db.example_table3 .... INFO [pool-6-thread-3]: cmd=source:xxx.xxx.xxx.xxx get_able : tbl=hive.problem_db.problem_table (이후로 pool-6-thread-3에 대한 log는 기록되지 않음 ) |
Hive가 재시작 되자마자 문제의 thread는 Hive에 존재하는 모든 테이블에 대해 "get_table"을 수행했습니다. 하지만 문제의 "problem_table" 차례가 되었고, 이후로는 pool-6-thread-3의 log는 기록되지 않았습니다. 이것을 근거로 "problem_table"이 Metastore heap memory 문제의 원인이라는 것을 알게 되었습니다.
이후로 문제를 해결하기 위해 "problem_table"에 drop 명령어도 수행했지만, 결과는 오히려 Metastore heap memory 증가 속도만 높일 뿐 쿼리 자체는 수행되지 않았습니다. 그래서 문제 테이블의 metadata 자체를 삭제하기 위해 RDB에 접속해 metadata를 분석했습니다.
RDB에서 metadata 분석
이전 글 중 [Hive] Unable to fetch table .null 에러 해결 방법 에서 RDB에 직접 접근해 metadata를 삭제했던 경험이 있었습니다. 하지만 이번 이슈의 원인을 좀 더 파악하기 위해 여러 가지 metadata를 살펴봤습니다. 그중에서 위의 분석 과정에서 계속 언급이 되었던 column privilege와 관련이 있어 보이는 "TBL_COL_PRIVS"라는 테이블을 발견했습니다.
MariaDB [Hive_DB]> show tables;
+--------------------+
|Tables_in_Hive_DB |
+--------------------+
|AUX_TABLE |
|BUCKETING_COLS |
|CDS |
|.... |
|TBL_COL_PRIVS |
|.... |
+--------------------+
SQL을 통해 "problem_table"의 TBL_ID를 알아냈고 TBL_COL_PRIVS 테이블의 데이터를 확인했습니다.
( 아래 결과는 필요한 column만 적었습니다. )
MariaDB [Hive_DB]> select * from TBL_COL_PRIVS where TBL_ID=111 limit 100;
+------------+--------+---------------+-------------+-------+
|COLUMN_NAME |GRANTOR |PRINCIPAL_NAME |TBL_COL_PRIV |TBL_ID |
+------------+--------+---------------+-------------+-------+
|col_name1 |ranger |user_name1 |ALTER |111 |
|col_name1 |ranger |user_name1 |CREATE |111 |
|col_name1 |ranger |user_name1 |DROP |111 |
|col_name1 |ranger |user_name1 |INDEX |111 |
|col_name1 |ranger |user_name1 |LOCK |111 |
|col_name1 |ranger |user_name1 |READ |111 |
|col_name1 |ranger |user_name1 |SELECT |111 |
|col_name1 |ranger |user_name2 |ALTER |111 |
|col_name1 |ranger |user_name2 |CREATE |111 |
|... |... |... |... |... |
+------------+--------+---------------+-------------+-------+
테이블의 내용을 확인해보니 Ranger policy에 근거한 모든 column의 privilege 정보들이었습니다. 즉 1개의 column당 권한을 받은 유저, 각 유저당 권한의 종류가 존재했습니다. 즉 1개의 테이블당 [모든 column 수] x [유저 수] x [권한 종류]의 row 수를 가지게 됩니다. (Ranger 관련 권한 한정 )
하지만 아래 SQL들을 통해 이상한 점을 발견할 수 있었습니다. ( 아래 수치는 극단적인 예시입니다. )
MariaDB [Hive_DB]> select count(*) from TBL_COL_PRIVS;
+-----------+
|count(*) |
+-----------+
|50,000,000 |
+-----------+
MariaDB [Hive_DB]> select count(*) from TBL_COL_PRIVS where TBL_ID=111;
+-----------+
|count(*) |
+-----------+
|49,500,050 |
+-----------+
Hive의 모든 테이블의 모든 column privilege 데이터 수가 5000만 건이지만, 문제 테이블이 4950만 건으로 전체의 99% 비중을 차지하고 있었습니다. 그래서 도대체 4950만 건은 어떤 내용일까?라는 생각으로 내용을 분석했습니다. 위에서 언급한 row 수를 계산했을 때 550만 건이 나와야 정상이었습니다.
MariaDB [Hive_DB]> select distinct create_time from TBL_COL_PRIVS where TBL_ID=111;
+-------------+
|create_time |
+-------------+
|1 |
|2 |
|3 |
|4 |
|5 |
|6 |
|7 |
|8 |
|9 |
|10 |
+-------------+
MariaDB [Hive_DB]> select count(create_time) from TBL_COL_PRIVS where TBL_ID=111 and create_time=1;
+---------------------+
|count(create_time) |
+---------------------+
|5,500,000 |
+---------------------+
...
MariaDB [Hive_DB]> select count(create_time) from TBL_COL_PRIVS where TBL_ID=111 and create_time=9;
+---------------------+
|count(create_time) |
+---------------------+
|5,500,000 |
+---------------------+
MariaDB [Hive_DB]> select count(create_time) from TBL_COL_PRIVS where TBL_ID=111 and create_time=10;
+---------------------+
|count(create_time) |
+---------------------+
|50 |
+---------------------+
위의 결과를 통해 8번의 중복 데이터가 있다는 것을 알게 되었습니다. create_time이 총 10번이었고, 그중 8번은 가장 첫 번째와 데이터 수 및 내용도 동일했기 때문입니다. (나머지 1번 50건은 Ranger에서 HDFS 관련 policy입니다.) 결국 비정상적으로 생성된 column privilege 데이터들이 RDB에 metadata로 존재했기 때문에, Metastore가 문제 테이블의 metadata를 가져오는 과정에서 거대한 양의 객체를 필요로 했고 이는 곧 Heap memory full과 Old GC를 발생시켰습니다.
그래서 "problem_table"의 column privilege 데이터들을 TBL_COL_PRIVS 테이블에서 모두 삭제했습니다.
MariaDB [Hive_DB]> DELETE FROM TBL_COL_PRIVS where TBL_ID=111;
Query OK, 49,500,050 rows affected
이후 Hive 쿼리로 문제 테이블을 drop 하는 데 성공했고, Hive 시스템도 정상적으로 돌아와 쿼리 수행이 가능해졌습니다.
결론
- 해당 이슈는 Ranger policy 관련 column privilege metadata가 RDB에 중복으로 생성된 것이 원인.
- Hiveserver2가 기동될 때 Metastore에 모든 DB, Table, Column privilege를 refresh 요청.
- 매번 약 4950만 개의 객체를 Metastore에서 사용, 이는 heap memory 증가와 Old GC를 발생시킴.
- RDB에서 문제 테이블의 column privilege 데이터들을 모두 삭제시키고 Hive에서 테이블을 drop 시킴.
- Hive 및 쿼리 수행 정상화되었음.
'Hadoop Ecosystem > Hive' 카테고리의 다른 글
| [Hive] IntelliJ로 Runtime Debugging하기 (0) | 2022.11.12 |
|---|---|
| [Hive] limit 사용 시 leastNumRows 에러 발생 이슈 (0) | 2022.11.04 |
| [Hive] Hive 아키텍처와 HiveServer2 & Hive Metastore (0) | 2022.07.01 |
| [Hive] Unable to fetch table .null 에러 해결 방법 (0) | 2022.05.30 |
| [Hive] Metastore & MySQL 문제로 Hive Query 실행 안되는 이슈 해결 방법 (0) | 2022.05.04 |