![[Review] 분단된 데이터를 2000 노드 이상의 단일 데이터 플랫폼에 통합(LINE)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fo0tAY%2FbtrJuSZf2te%2FAAAAAAAAAAAAAAAAAAAAAGazLwHkOlkhFP2tWo1dZCvuenZHuEPmOZdMOYaZ1m4y%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DlP0N4r73Up2yCoWKAHCxm9PIY%252FM%253D)
본 게시물은 기업 컨퍼런스 발표 자료 및 영상을 요약 및 리뷰하는 글입니다.
저작권에 문제가 있다면 연락 부탁드립니다.
Conference
LINE DEVELOPER DAY 2021
LINE DEVELOPER DAY 2021은 11월 10일부터 11일까지 이틀간 열리는 온라인 기술 컨퍼런스입니다. 다양한 엔지니어가 참여해 여러 분야에 걸쳐 첨단 기술과 도전 경험, 직면하고 있는 과제에 대해 공유합
linedevday.linecorp.com
Slide
Video
발표에 대한 내용을 요약하며 제 개인적인 생각은 초록색으로 작성하겠습니다.

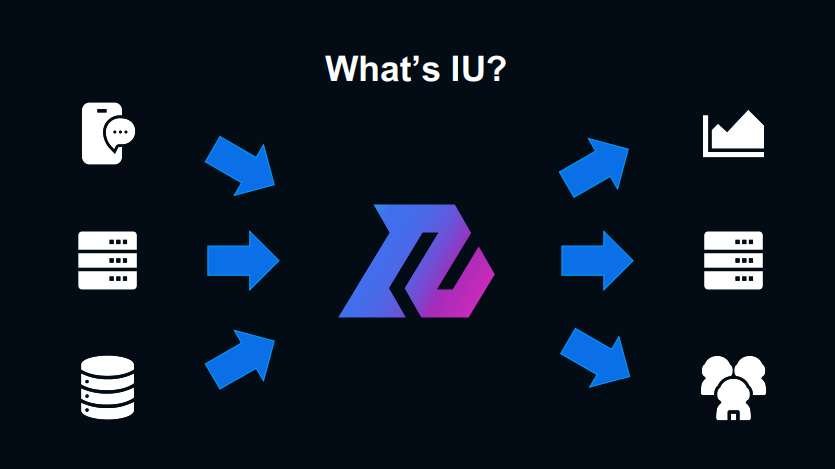
라인에서는 모든 데이터를 축적하고 사용할 수 있는 데이터 플랫폼을 IU라고 부르고 있습니다. 데이터 수집에서부터 이용 활용까지 일관해서 담당하고 있습니다.
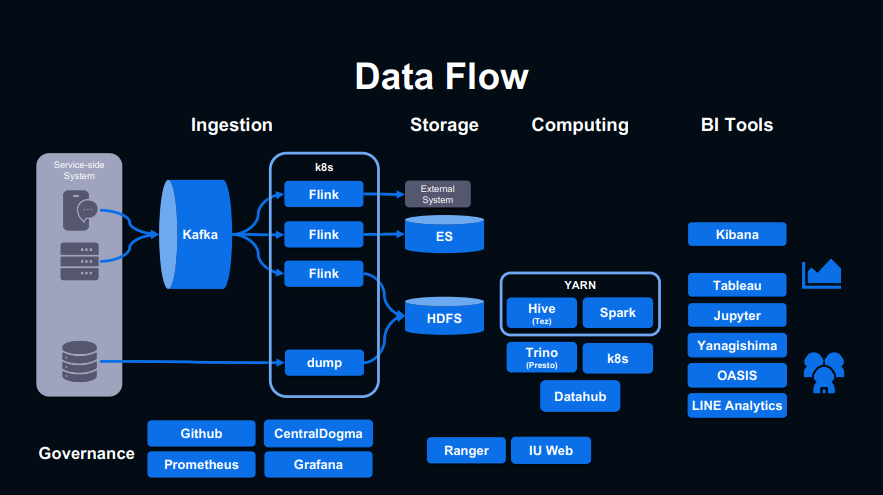
위의 그림은 IU의 데이터 파이프라인입니다. 기본적으로 Kafka를 이용해 데이터를 수집하고 있고, k8s 기반의 Flink를 통해 HDFS, Elasticsearch 등 여러 시스템에 데이터를 축적시키고 있습니다. 처리를 위한 시스템으로 Spark를 절반 이상 사용하고 있습니다. 분석을 위한 툴로써 Kibana와 Tableau, Jupyter를 사용하고 자체적으로 개발한 Yanagishima, OASIS, LINE Analytics를 사용합니다.

인프라적인 측면에서 플랫폼의 규모는 400PB의 HDFS 용량, 5000대 이상의 노드, 90,000개의 vCore를 가집니다.

그리고 데이터를 사용하는 데 있어 Hive 테이블만 4만 개, 하루에 돌아가는 job의 수는 15만 개입니다.
LINE이 대규모 플랫폼을 사용한다고 들었지만, 사실 이 정도로 큰 규모일지는 몰랐습니다. 데이터 플랫폼을 위한 노드만 5,000대 이상이라는 것에 LINE의 인프라와 기술을 짐작할 수 있었습니다.


하지만 지금의 IU가 만들어지기 전에 LINE은 플랫폼에 문제를 가지고 있었습니다. 그 문제는 Datachain, Datalake라는 사용하는 조직이 다른 클러스터가 2개가 존재했습니다. 데이터가 쌓이고 플랫폼이 거대해지면서 두 클러스터의 관계는 점점 복잡하게 얽히게 되었습니다. 실제 사용을 위해서는 두 클러스터를 모두 사용해야 하지만 억지로 구분해야 하는 상황이 늘어났습니다.

이로 인해서 생기는 문제가 크게 3가지가 있었습니다.
첫 번째는 테이블 Catalog가 각 클러스터에 분리되어 있어 결합이 안 되는 점입니다. 이렇게 테이블 Catalog가 분리되어 있기 때문에 두 클러스터에 각각 존재하는 데이터를 결합해서 보기 위한 코스트가 상당히 컸습니다. 그리고 데이터 교환 및 권한 설정 또한 코스트가 발생했습니다.
두 번째는 리소스 공유가 안된다는 점입니다. 초기 각 클러스터 리소스 할당에 있어 적절하게 나누어지지 않았던 것이 특정 클러스터는 리소스가 남아있음에도 불구하고 다른 클러스터는 리소스가 부족한 현상으로 이어졌습니다.
세 번째는 권한의 단절입니다. 데이터를 통합해서 보기 위해 데이터 복사는 빈번하게 이루어졌습니다. 하지만 각 클러스터에서 권한 관리를 따로 관리하고 있기 때문에 동일한 데이터에 대해 클러스터마다 권한 체계가 바뀌어버리는 문제가 발생했습니다.
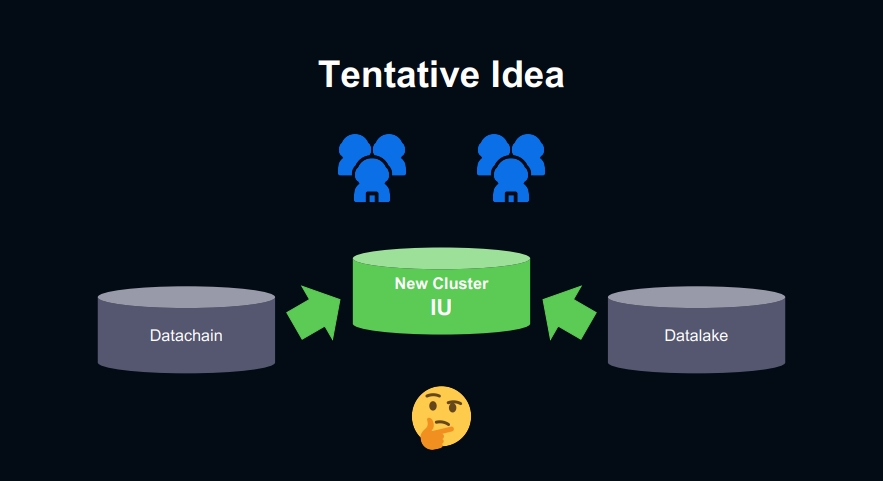
이러한 문제들을 해결하기 위해 통합된 플랫폼을 구축하기로 했습니다.

하지만 이렇게 대규모 플랫폼 2개를 하나로 통합하는데 많은 난관이 존재했습니다.

첫 번째로는, 대량의 데이터를 어떻게 신규 클러스터에 옮길 것인가? 데이터를 한꺼번에 옮기는 작업을 하게 된다면 데이터들의 의존 관계는 엉망이 되고 다양한 문제들이 발생할 것입니다. 그리고 Hadoop의 distcp를 이용하면 많은 YARN 리소스를 사용하게 되어 클러스터의 vCore와 메모리가 부족해질 수 있습니다. 이러면 기존에 데이터 플랫폼에 상관없는 서비스까지 영향을 줄 수 있습니다.

두 번째로는 데이터 이전에 있어서 어떤 데이터를 먼저 진행할 것인가? 플랫폼에서 테이블 간의 의존 관계가 복잡하게 얽혀있었기 때문에 조직 간의 데이터 통신도 빈번했습니다. 이는 특정 테이블을 먼저 이전함에 따라 의존성이 높은 다른 테이블을 사용하지 못하는 문제가 발생할 가능성이 있었습니다.

세 번째로는 원하는 데이터가 신규 통합 플랫폼과 기존 플랫폼 중 어디에서 active 한 상태인 것인가? 신규 플랫폼을 사용하는 데 있어 100% 이전이 되기 전까지는 기존 플랫폼을 사용해야 하는데 사용자는 내가 원하는 데이터가 어디에서 사용 가능한지 혼란을 가질 수 있습니다. 데이터 수집을 기존, 신규 플랫폼 모두에 진행하는 방법도 있었지만 이는 데이터 정합성 및 코스트가 상당히 컸습니다.
여기까지 발표를 들었을 때 LINE이 신규 플랫폼을 구축하는데 상당히 많은 고민과 어려운 문제를 직면하고 있다는 것을 알 수 있었습니다. 단순한 데이터 이전을 통한 통합 과정이라고 생각할 수 있겠지만, 위에서 언급한 대로 플랫폼 통합을 진행하면서 기존에 플랫폼에서 진행되던 분석 및 사용은 이전과 동일하게 이루어져야 하는 점이 가장 큰 문제이자 해결해야 하는 난관이라고 생각했습니다.

그래서 LINE에서는 위에서 말한 문제점들을 해결하면서 IU를 구축할 방법들을 제시합니다. 접근 방법을 크게 두 가지로 나누게 되는데, 첫 번째는 기술적 접근으로 복잡한 이슈나 시스템을 간소화합니다. 두 번째는 데이터 관리적 접근으로 지금 현재 사용되는 시스템을 최대한 바꾸지 않고 이관하려고 했습니다.
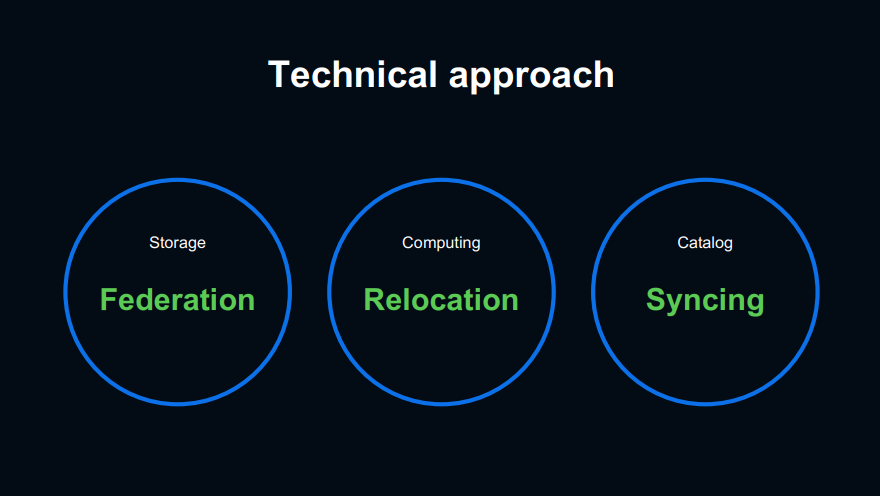
기술적 접근은 크게 세 가지로 나눠집니다. 데이터를 보관하는 Storage, 리소스를 가지고 연산하는 Computing, 플랫폼에서 사용되는 데이터의 metadata를 관리하는 시스템인 Catalog로 분류되며 이 세 가지를 통합하기 위한 기술적인 접근을 소개합니다.


Storage 부분은 HDFS에서 제공하는 Federation 기능을 이용하여 해결할 수 있었습니다. Federation을 통해서 IU 클러스터에서도 Datachain, Datalake 클러스터에 접근할 수 있었고 이는 곧 Client가 서로 다른 세 클러스터에 모두 접근할 수 있게 되었습니다. 그래서 IU 클러스터로 데이터를 복사하거나 double write를 할 필요가 없어졌기 때문에 앞서 언급한 데이터 이전에 관한 문제는 자연스럽게 해결되었습니다.


Computing 부분은 기존 클러스터의 장비들을 IDC수준의 대규모 물리적 이동을 통해 새로운 데이터 센터로 옮기면서 해결했습니다. 100대~200대 정도로 단계적으로 장비 이동을 했습니다. 노드를 decommission 하는 과정에서 리소스 부족을 최소화하고자 여유가 있던 DataChain 클러스터의 이동을 먼저 진행했습니다. 구 클러스터의 YARN 리소스는 계속 줄어들지만 Catalog 이관은 아직 진행되지 않았습니다. 그래서 구 클러스터의 Metastore를 계속해서 사용하는 것을 대응하기 위해 Catalog는 구 클러스터, YARN 리소스는 신규 클러스터에서 사용하도록 하는 "Hybrid Hive"라는 기술적 대응을 했습니다.


Catalog 부분은 Metastore의 DB 이벤트를 구 클러스터에서 IU로 동기화하는 Metastore Sinker를 개발하여 해결했습니다. Hive에서는 MetastoreEventListener라는 추상 클래스가 제공하는데, Hive DB 이벤트 중 DDL 계열의 Table, Partition 작업들을 trigger 삼았습니다. Trigger가 발생하면 Json 형태로 Kafka로 전송하고 SyncWorker라는 Kafka Consumer가 배치 작업을 데이터를 가져옵니다. LINE의 오픈소스인 설정 관리 툴 Central Dogma를 이용해 SyncWorker에서 필터링 및 변환 같은 전처리 작업을 진행하고 IU Metastore에 저장합니다.

기술적 접근 다음으로는 데이터 관리적 접근입니다. 데이터 이관에 있어 변경점을 최소화해서 이관의 허틀을 낮추는데 주력했습니다.

Endpoint Switching은 Endpoint 주소만 바꿔줌으로써 데이터를 사용할 수 있는 내용입니다. 구 클러스터와 신규 클러스터를 같이 사용하게 되면 데이터 정합성이나 복잡성의 증가를 우려했기 때문에 목적지를 IU만 지정해서 사용할 수 있도록 했습니다. 이를 위해서는 테이블을 사용하는 데 있어 실제 데이터, 테이블 정보 두 가지로 나눠서 생각해야 합니다.
실제 데이터의 경우 HDFS federation을 통해서 구 클러스터에 있더라도 사용이 가능했습니다. 그래서 기존의 데이터 파이프라인을 그대로 사용하면서 구 클러스터에 저장을 하기 때문에 데이터 정합성의 문제는 고려 대상에서 제외되었습니다. 테이블 정보에 대한 참조의 경우 Metastore Sinker 덕분에 구 클러스터 테이블 정보를 IU Metastore에서도 참조가 가능했습니다.
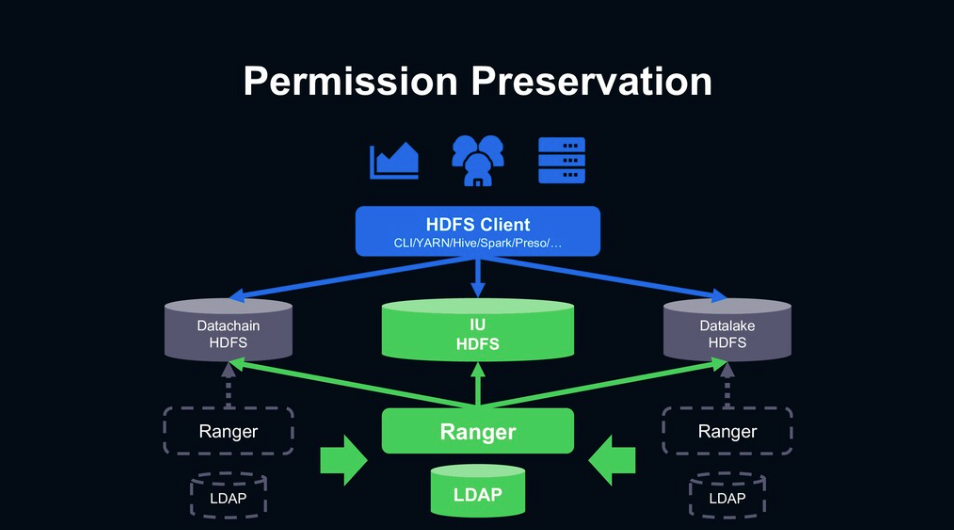
Permission Preservation은 구 클러스터의 권한을 그대로 유지하며 사용하는 내용입니다. HDFS federation 적용과 기존에 각 클러스터에 나눠져 있던 Ranger, LDAP 시스템들을 각각 통합하면서 해결했습니다. 기존 데이터는 구 클러스터에 있기 때문에 필요한 권한 내용은 기존과 동일합니다. 그래서 유저 관리의 LDAP, 권한 관리의 Ranger를 각각 신규 클러스터에 통합했습니다.

Tiered Stakeholders은 중요도와 복잡도에 따라 단계적으로 데이터를 나누는 내용입니다. 각 조직 간의 데이터 의존성 등 여러 가지를 고려하여 맞춤형 이관 절차를 제시했습니다. 위의 그림처럼 3 티어로 분류했습니다. 1 티어는 raw 데이터와 전사적으로 사용되고 있는 데이터 생성을 맡고 있는 데이터 플랫폼입니다. 그리고 2 티어는 이러한 raw 데이터를 이용해 고도의 데이터 모델을 생성하는 머신러닝 팀, 마지막으로 3 티어는 데이터를 이용 및 활용을 하여 서비스 또는 대시보드를 관리하는 서비스 사이드 팀입니다.
데이터 이관에 있어 각 조직 간의 문제가 발생하는 것을 최소로 하기 위해 하위 티어부터 순서대로 이관을 진행했습니다. 그렇다면 왜 하위 티어부터 이관을 진행했을까요? 티어 3에서 이관을 진행한다고 가정했을 때 1,2 티어는 이미 Metastore sinker를 통해 IU에 데이터가 준비된 상태라 티어3은 IU로 이관만 하면 데이터 생성이 가능했습니다. 그리고 이관 과정에서 구 클러스터에 없어지게 되더라도 상위 티어들은 티어3에 대한 데이터 의존성이 없기 때문에 문제가 없습니다.

위에서 기술한 대로 기술적, 데이터 관리 측면에서 각 3가지를 고려하며 이번 프로젝트를 진행했습니다.

마지막으로 향후 IU를 사용하는 데 있어 도전 과제입니다. 첫 번째, Data Democracy로써 IU를 더 진화시켜 데이터의 보안 수준을 적절히 관리하며 데이터 활용을 촉진시킬 예정입니다. 그리고 Atlas를 도입하여 데이터 리니지를 통해 의존 관계나 권한 위임의 효율성을 높일 예정입니다. 두 번째, ML을 더 좋은 환경에서 사용하기 위해 Iceberg 도입으로 데이터 생성, 이용 및 활용까지 속도를 올리고 서비스 연계를 높일 것입니다. 그리고 Capacity planning도 더 욱 큰 관점에서 진행하여 다양한 분야에서 ML을 진행해도 충분한 성능이 나오도록 할 것입니다.
여기까지 LINE에서 소개한 IU 도입 및 플랫폼 통합 과정이었습니다. 기존에 존재하던 두 클러스터 또한 대규모 플랫폼이었지만, LINE에서는 이에 만족하지 않고 문제점을 극복하기 위한 노력들을 많이 한 것 같습니다. 무엇보다도 이러한 대규모 프로젝트는 시작하기에 앞서 막연한 리스크만 떠올리며 시작하기 힘들었을 텐데 이를 기술적으로 잘 풀어나간 것이 상당히 인상적이었습니다. 이번 세미나를 통해 다시 한번 느낀 것은 내가 현재 사용하고 있는 기술을 깊게 알면 알수록 트러블 슈팅을 더욱 빠르고 효과적으로 할 수 있다는 것입니다. 기술적인 실력이 바탕이 되어야 작은 경험도 가치가 생기고 그 안에서 배울 점을 알 수 있다고 생각합니다. 이번 세미나를 보니 깊고 탄탄한 기본기와 기술력을 꼭 가지고 있어야겠다는 생각을 했습니다!