![[Hadoop] MapReduce - Simplified Data Processing on Large Clusters](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpowkT%2FbtrwhchNIPT%2F2FXnnsLm5SJToBuj4KBf91%2Fimg.png)
MapReduce란?
HDFS에 저장되어 있는 빅데이터를 효율적으로 작업 및 처리를 하기 위한 분산 프로그래밍 모델
HDFS에 이어서 이번 글에서는 MapReduce 를 소개하겠습니다. HDFS를 공부했다면 "데이터는 HDFS에 저장해서 여러 DataNode에 저장되어 있는데 이 데이터를 어떻게 사용하지?"라는 궁금증이 생길 수 있습니다. HDFS에 저장되어있는 데이터를 사용하기 위해서 작업을 수행하는 서버로 데이터를 불러와 직접 어플리케이션을 실행시킬 수 있겠지만, 이것은 올바른 빅데이터 사용법이 아닙니다. 왜냐하면 상당히 큰 양의 데이터를 HDFS에 저장했는데, 작업을 위해서 이 데이터를 다시 작업 서버로 가져오는 비용은 데이터 양이 커짐에 따라 증가하기 때문입니다. 그래서 올바른 빅데이터 사용법은 데이터가 HDFS에 존재한채로, 작업을 수행할 어플리케이션이 직접 각 DataNode에서 실행되는 것입니다. 이러한 작업을 위한 프로그래밍 모델이 MapReduce 입니다.
MapReduce의 동작 원리
MapReduce 가 동작하는 방식으로는 크게 Map phase, Shuffle phase, Reduce phase로 나누어집니다. 가장 큰 핵심으로는 MapReduce 가 데이터를 key / value 방식으로 처리한다는 점입니다.
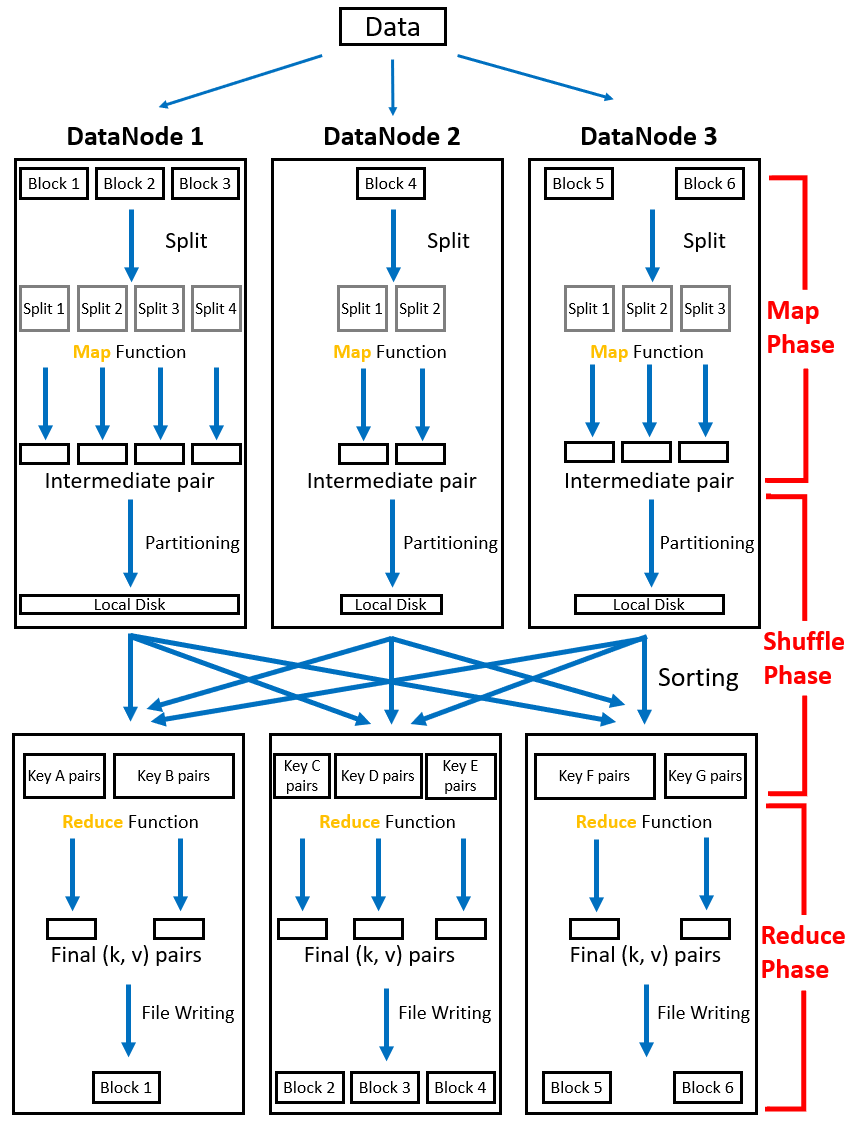
Map Phase
Map 함수에서는 input 데이터를 읽어와 사용자가 직접 정의한 내용에 맞게 job이 수행됩니다. Input 데이터는 사용자가 직접 정의한 Map 함수에 의해 key / value로 저장되어 Map 함수의 output이 됩니다. 위의 그림을 보면 어떠한 데이터가 3개 DataNode에 분산되어 block으로써 저장이 되어있습니다. 저장되어 있는 Block 상태에서 Map 함수를 통해 kay / value 리스트가 도출되는 과정까지 Map phase입니다.
이전 글에서 설명한 HDFS 원리에 의해 파일은 다수의 Block으로 DataNode들에 분산적으로 저장됩니다. 그리고 빅데이터의 올바른 사용 방법으로써 데이터가 있는 곳에서 작업이 수행되어야 하기 때문에 Map 함수는 각각의 DataNode에서 수행됩니다. 이 때 DataNode에 저장되어 있는 Block들은 여러 개의 Split으로 쪼개지고 이렇게 쪼개진 Split 마다 Map task가 부여됩니다. 즉, Split 1개당 Map task 1개가 부여되어 데이터가 처리되고 key / value 리스트들을 output으로 도출합니다. 이 때 output으로 나온 리스트들을 intermediate pair라고 부릅니다. Block과 Split간의 차이에 대해서 궁금증이 있을 수 있습니다. 해당 내용은 뒤에서 자세하게 다루겠습니다.
Shuffle Phase
Shuffling은 Map 함수의 결과들로 나온 intermediate pair중에서 같은 key 값을 가지는 pair끼리 묶어 key를 기준으로 정렬 후 Reduce 로 전달하는 작업을 수행합니다. Shuffling 과정을 좀 더 상세하게 설명하겠습니다.
Shuffling 작업 중에서 각 key 값을 Reduce 에 배정하는 것을 partitioning이라고 합니다. Partitioning 작업은 기본적으로 hashing을 이용해 key 값들을 주어진 Reduce 에 배정시키기 때문에 여러 키 값들을 적절히 밸런스에 맞게 분배를 시킵니다. 하지만 partitioning 작업은 사용자 정의에 의해 hashing이 아닌 다른 방법이 사용될 수 있습니다. Partioning이 진행된 후 데이터들은 각 DataNode의 local disk에 저장됩니다.
각 key 값이 partitioning을 통해 Reduce 를 배정받았다면 각 DataNode들 간의 통신(Remote Procedure Calls)을 하면서 key 값들을 Sorting 해줍니다. 이 과정을 통해 서로 흩어져 있던 동일한 key 값들은 한 곳으로 모이게 되면서 partioning을 통해 배정받은 Reduce 에 input 데이터로 전달됩니다. 여기서 알아야할 점은 Map phase와 바로 다음 설명할 Reduce phase에서는 각 노드들간의 통신을 전혀 하지 않는다는 것입니다. 이 점이 MapReduce의 신뢰성이 높은 이유입니다.
Reduce Phase
Map 함수가 파일을 여러 split으로 쪼개어 분산 처리를 했다면, 반대로 Reduce 는 분산 처리된 결과를 다시 합쳐주는 작업을 진행합니다. 그 결과로 key / value 데이터를 output으로 도출하고 다시 HDFS에 block으로써 저장됩니다.
각 pair들이 Reduce 에 전달될 때는 1개 이상의 value 값들을 가지고 리스트로써 input으로 들어갑니다. Reduce 는 사용자가 직접 정의한 내용에 맞게 input으로 들어온 key / value 리스트들을 처리합니다. 그래서 최종적으로 1개의 value값만을 가지는 key / value 데이터를 output으로 도출시킵니다.
이번글에서는 Hadoop component들 중 MapReduce 에 대해 소개했습니다. 간단하게 이해하고 넘어갈 수 있었지만 파일이 HDFS에 저장된 후부터 데이터의 관점에서 어떻게 Map, Shuffle, Reduce 과정이 이루어지는지 이해하다보니 글 쓰는데 상당히 많은 시간이 걸렸습니다. 직접 검색하고 공부한 시간에 비해 글의 양은 적게 나왔습니다. 수정할 내용이 있거나 추가해야할 내용이 있다면 즉각적으로 수정하겠습니다.
References
https://yeomko.tistory.com/31?category=878347
icecello.tistory.com/35?category=500353
'Hadoop Ecosystem > Hadoop' 카테고리의 다른 글
| [HDFS] JMX Metrics 값 불러오기 (0) | 2023.04.02 |
|---|---|
| [Hadoop] YARN Capacity scheduler 특징 및 Queue 옵션 (0) | 2022.04.22 |
| [Hadoop] HDFS NameNode의 Metadata 관리와 Failover 상세 과정 (0) | 2022.02.15 |
| [Hadoop] YARN - Yet Another Resource Negotiator (0) | 2021.06.12 |
| [Hadoop] HDFS - The Hadoop Distributed File System (0) | 2021.03.14 |