![[Spark] Spark란? - Cluster Computing with Working Sets](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FkLHjC%2Fbtq17anIFis%2FAAAAAAAAAAAAAAAAAAAAACpLnhHZruLsMTLgTxbqopv-g6dAUPKMA_v10VkPzm6y%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DYJNdvP0doBQ8qfoy97UqnWzByBs%253D)
Spark란?
Cluster 환경에서 In-Memory를 사용해 빠른 데이터 작업을 하기 위한 프레임워크.
MapReduce에 이어서 이번 글에서는 Spark 를 소개하겠습니다. 사실 MapReduce 다음 주제로 Yarn을 정하려고 했지만 공부를 하다 보니 Spark 를 하게 되었고 MapReduce와 비교하며 설명하는 것도 나쁘지 않을 것 같아 Spark 로 정하게 되었습니다.
Spark란?
Spark 라는 것은 MapReduce와 비슷하게 HDFS에 저장되어 있는 데이터를 작업하고 처리하기 위한 프레임워크입니다. Java 언어로 작성해야 했던 MapReduce와 달리 Spark 는 Scala, Python, Java 등 다양한 언어로 프로그래밍이 가능하고 In-Memory 기반의 빠른 연산을 이용하기 때문에 최근에는 MapReduce를 대체해 많이 사용되고 있습니다.
그렇다면 In-Memory 기반의 작업이 MapReduce와 어떤 차이가 있어서 속도가 더 빠를까요? MapReduce의 경우 Map, Reduce 함수로 작업을 수행하는 프레임워크로 데이터의 Read / Write는 HDFS를 통해서 이루어집니다. 그래서 여러 개의 Job을 연속적으로 수행해야 할 때 Map, Reduce 함수가 반복적으로 수행되고 Reduce가 끝날 때마다 데이터는 HDFS에 저장되고 Map 함수가 시작할 때 다시 HDFS에 접근해야 합니다. 불필요한 disk Read / Write가 수행되기 때문에 시간이 오래 걸립니다.
이러한 단점에 있어 Spark 는 disk 접근을 최소화하기 위해 memory를 cache처럼 사용합니다. 그래서 필요한 데이터가 memory에 존재하면 시간이 오래 걸리는 HDFS, 즉 disk 접근은 생략해도 됩니다. 아래의 그림을 보면 쉽게 이해할 수 있습니다.

Spark의 위치
Spark 는 빅데이터 플랫폼에서 Resource를 관리하는 YARN 위에 위치하고 있습니다. Spark 가 나오기 전에는 MapReduce가 아래 그림에서 Spark 의 자리에 위치했었습니다. 앞선 글에서는 Map, Reduce 함수를 통한 분산 처리 방식을 이용하는 MapReduce의 장점을 소개했습니다. 하지만 단점으로 MapReduce를 한번 이용할 때마다 HDFS에서 데이터를 읽고 다시 저장하기 때문에 불필요한 데이터 Read / Write가 필요하다는 점을 언급했습니다. Spark 는 이러한 단점을 보완함으로써 MapReduce 자리를 대신할 수 있었습니다.

Spark 구조
Spark 의 구조로는 크게 Driver, Executor, Cluster manager로 나누어집니다. 각각에 대해 설명한 후 Spark 의 동작 과정을 알아보겠습니다.
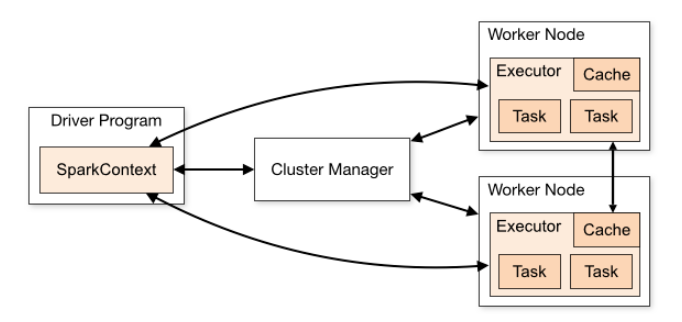
Driver
Driver는 Spark 의 main을 실행하는 process입니다. Spark application의 master / slave 중 master 역할로써 주로 Cluster manager에게 resource를 요청, job scheduling 등 관리자 역할을 담당하고 있습니다.
Cluster Manager
Cluster manager는 Spark application 수행에 있어 resource을 관리하는 역할을 담당합니다. Cluster manager는 Spark 와는 별개의 프레임워크로 대표적으로 YARN, MESOS, Kubernetes가 있습니다. ( 외부 프레임워크 대신에 자체적인 시스템을 사용하는 StandAlone 방식도 있긴 하지만 주로 외부 프레임워크를 사용합니다. )
Executor
Executor는 Spark application의 실질적인 수행을 담당하는 프로세스입니다. Spark application의 master / slave 중 slave 역할을 하고 있습니다. Resource를 관리하는 Cluster manager로부터 생성이 되어 이후 Driver에게 수행 code를 전달받고 Cluster Manager에게 task를 할당받습니다. 이때 task는 thread에 의해 수행되기 때문에 Executor당 여러 개의 task가 할당될 수 있습니다. 그리고 Application에서 RDD를 저장하기 위한 cache를 가지고 있습니다.
Spark 동작 과정
Spark 의 동작 과정은 User가 Spark shell에서 작업을 수행하는 client mode와 Spark-submit을 하는 cluster mode 두 가지로 나누어집니다. 이때 cluster manager는 가장 많이 쓰이는 YARN이라고 가정해서 과정을 설명하겠습니다.
Client mode
Client mode라는 것은 User가 local machine에서 Spark shell을 통해 application을 실행하는 방법을 말합니다. Spark 동작 과정은 아래와 같습니다. 큰 특징으로는 Driver가 Spark shell을 실행하는 local machine에서 생성된다는 점입니다. 참고로 아래 그림에서 Application Master는 생략했지만 실제로는 생성됩니다.
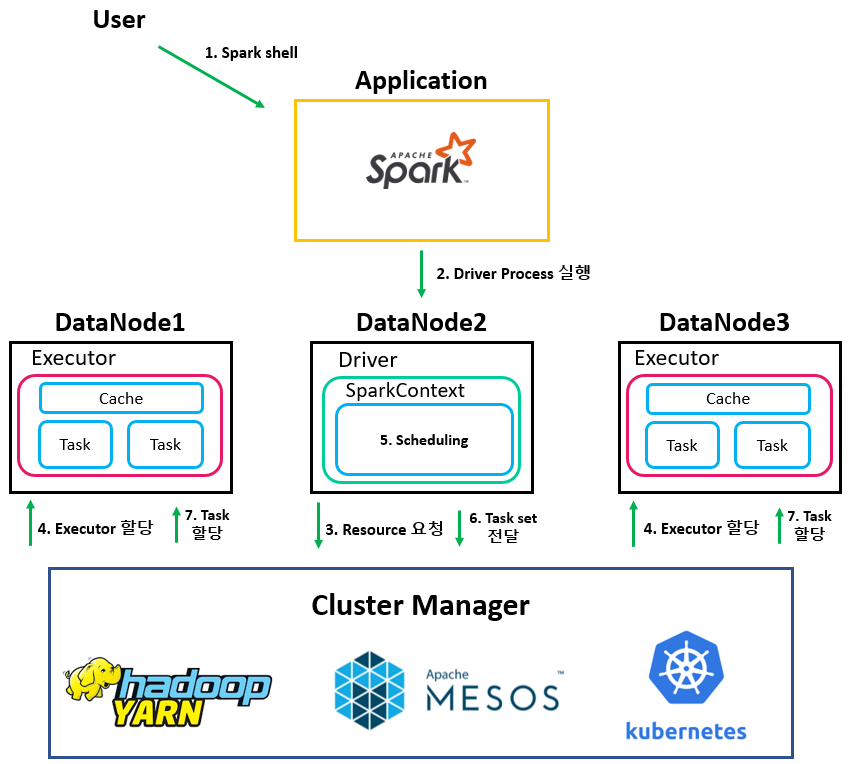
| 1. User가 Spark shell에 접속. 2. Spark shell에 접속함과 동시에 해당 local machine에 Driver를 실행. 3. Driver는 SparkContext 객체를 생성하고 SparkContext는 Cluster manager에게 Resource 요청. 4. Cluster manager는 resource 계산 후 직접 Executor들을 여러 노드에 할당. 5. SparkContext는 코드 상에서 Action이 수행될 때 DAG 및 Task scheduling 수행. 6. Scheduling 결과로 나온 task들을 Cluster Manager에게 전달. 7. Cluster Manager는 각 Executor에게 task 할당. |
Cluster mode
Cluster mode라는 것은 User가 Spark-submit을 이용해 application을 실행시키는 방법을 말합니다. (참고로 Spark-submit은 Client 모드 실행도 가능합니다.) Spark 동작 과정은 아래와 같습니다. Client mode와 비교되는 특징으로는 Driver 위치가 YARN에 의해 만들어진 Application Master container이기 때문에 DataNode 중 하나에서 생성됩니다. 즉 local machine에 대한 의존성을 가지지 않습니다.
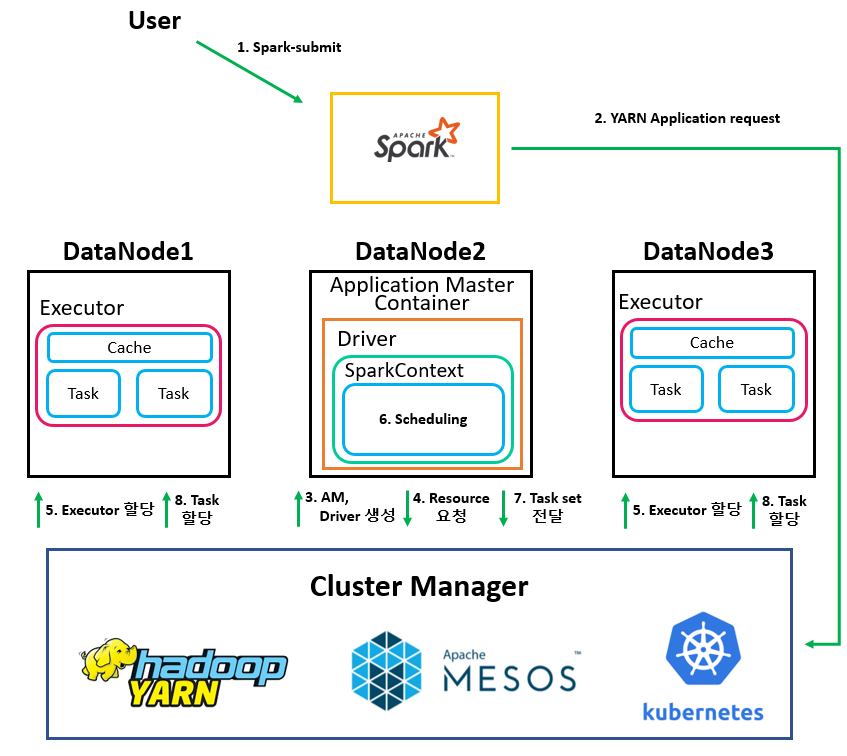
| 1. User가 Spark-submit을 통해 application을 실행. 2. Spark는 YARN에게 application request 수행. 3. YARN은 DataNode에 Application master를 생성하고 AM container에 Driver 실행. 4. Driver는 SparkContext 객체를 생성하고 SparkContext는 Cluster manager에게 Resource 요청. 5. Cluster manager는 resource 계산 후 직접 Executor들을 여러 노드에 할당. 6. SparkContext는 코드 상에서 Action이 수행될 때 DAG 및 Task scheduling 수행. 7. Scheduling 결과로 나온 task들을 Cluster Manager에게 전달. 8. Cluster Manager는 각 Executor에게 task 할당. |
Client mode와 Cluster mode의 가장 큰 차이점은 Driver를 누가 생성하냐입니다. Client mode의 경우 Spark shell에 접속하는 순간 Driver가 실행되기 때문에 Spark shell이 실행된 노드에서 Driver가 생성됩니다. 하지만 Cluster mode의 경우 Cluster manager인 YARN이 AM 생성 후 AM container에서 Driver가 실행되기 때문에 어떤 노드에서 실행될지 모릅니다.
RDD 란?
RDD란 Resilient Distributed Dataset으로써 직역하자면 "쉽게 복원이 되는(탄력있는) 분산 데이터" 입니다. 뭔가 문제가 생겼을 때 쉽게 롤백시킬 수 있는 데이터처럼 들리는데 우선 왜 Spark 에서 이러한 특징의 데이터가 필요한 지부터 알아야 합니다.
위에서 Spark 를 소개한 것과 같이 기존의 MapReduce와의 큰 차이점이라고 한다면 In-Memory를 사용해 빠른 처리 속도가 가능하다는 것입니다. 즉, 연산에 필요한 데이터들을 disk가 아닌 memory에 저장하기 때문에 처리 속도가 훨씬 빨라집니다. 하지만 In-Memory 방식의 문제점은 무엇일까요? 서버에 문제가 생겼을 때 memory에 있는 데이터도 날아갈 수 있다는 점입니다. 즉 disk에 비해 안정성이 낮기 때문에 문제가 생기더라도 복구가 가능해야 합니다. 그래서 RDD라는 개념이 도입이 되었고 Spark 에 꼭 필요한 존재로 사용되고 있습니다.
( 참고로 Spark 버전이 올라감에 따라 RDD보다 성능이 좋은 Dataframe, Dataset이 나왔습니다. )
RDD Operation
RDD의 경우 두 가지의 operation으로 Transformation과 Action이 있습니다. Spark 의 가장 큰 특징이라고 할 수 있는 것은 Lazy Execution입니다. Lazy Execution이라는 것은 코드를 처리하지만 실제 데이터 연산 작업은 가장 마지막인 Action operation이 수행될 때 이루어지는 것입니다.
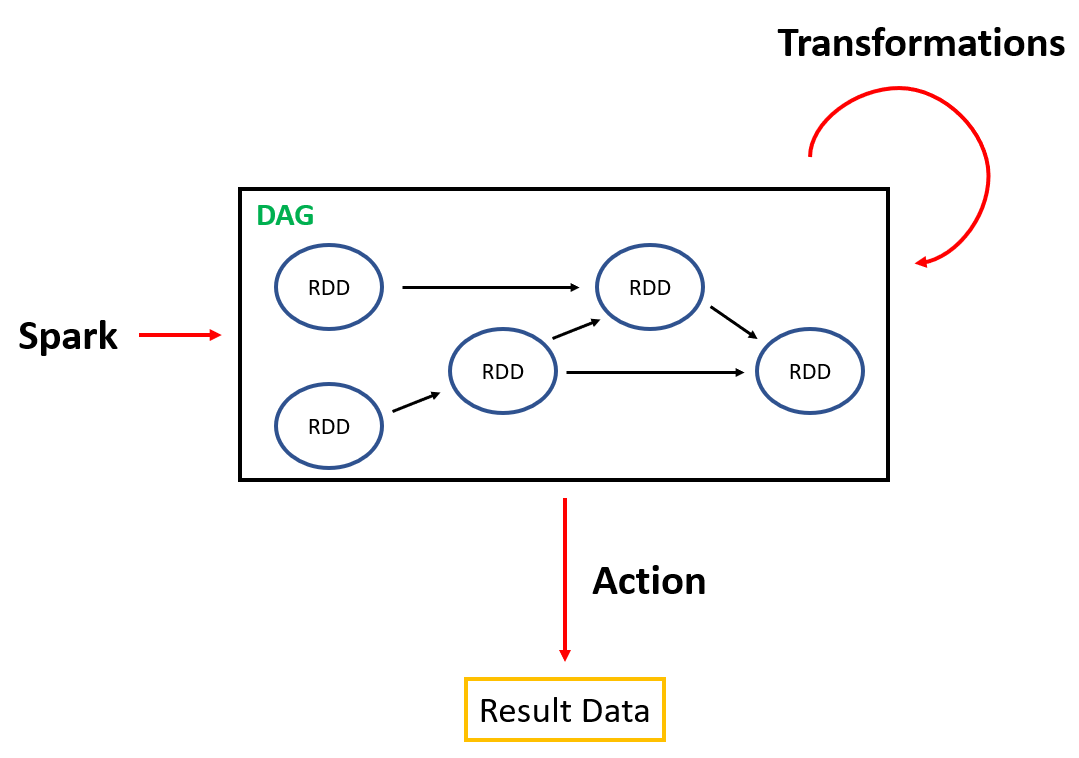
Transformation
RDD는 불변성으로 데이터를 수정할 수 없기 때문에 새로운 데이터를 위해서는 RDD를 새로 생성해야 합니다. 이 과정을 Transformation이라고 하고 RDD들의 생성 기록들을 Lineage라고 합니다. Spark 코드가 읽혀지면서 Transformation operation이 수행됩니다. Transformation이 수행될 때마다 새로운 RDD가 생성이 되고 RDD들은 DAG( Directed Acyclic Graph )의 형태를 이루고 있습니다. 이렇게 만들어진 RDD들은 실제로 데이터 연산이 이루어지지 않은 상태고 이후에 수행될 Action을 위해 만들어진 것입니다.
| Directed Acyclic Graph 각 edge의 방향성이 존재하고 node간의 cycle을 형성하지 않는 graph를 말합니다. |
Transformation 함수들
- map()
- flatMap()
- filter()
- distinct()
- union()
- groupByKey()
- mapPartition()
- ....
Action
Transformation을 통해 RDD들이 생성되며 DAG를 형성한다면, Action은 실제 연산을 수행하는 operation입니다. DAG scheduling을 통해 RDD들은 stage들로 변환됩니다. 그리고 최종적으로 stage들은 RDD의 partition 개수만큼 task들로 쪼개지고 각 task들은 Executor들에게 할당 및 수행되어 최종 결과 값이 반환됩니다.
Action 함수들
- collection()
- count()
- countByValue()
- reduce()
- foreach()
- aggregate()
- ...
Scheduling
Transformation에 의해 RDD가 생성되고 실제로 연산이 수행되는 Action과정에는 Scheduling이 포함되어 있습니다. DAG Scheduler에 의해 RDD -> Stage -> Task의 과정으로 나누어집니다. 이때 scheduling에 의해 나온 task들을 Cluster Manager에게 전달시키고 Cluster Manager는 task들을 각 Executor에 할당시킵니다. 아래의 그림을 보면 쉽게 이해할 수 있습니다.
( L : Load, T : Transformation, S : Shuffle, J : Join, A : Action )

지금까지 Spark 에 대해 알아보았습니다. 빅데이터 클러스터에서 많이 쓰이기 때문에 한 번쯤은 꼭 공부해야 하는 component들 중에 하나입니다. 다음 글에서는 이번 글에서 계속 언급이 되었던 YARN을 소개하도록 하겠습니다.