![[Spark] Spark structured streaming으로 Kafka topic 받기 #2 - Spark 및 Hadoop 서비스 실행하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDVUfp%2FbtrwgEFMvfx%2FAAAAAAAAAAAAAAAAAAAAAIexvt2gAD2WuI_-BLf10xG8a_YSqvqiJuleywBtgfFs%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DqaNRrTMPadiQV3QUqT5EldZdEbE%253D)
Docker
내가 원하는 환경의 서버를 container라는 개념으로 쉽게 생성 및 삭제할 수 있는 플랫폼.
Kafka
Publish, Subscribe 모델 구조로 이루어진 분산 메세징 시스템
Spark Streaming
Spark API 중 batch와 실시간 streaming이 가능한 Spark API
Hadoop & Spark 서비스 실행
이번 글에서는 Docker Compose를 이용하여 Hadoop과 Spark 서비스들을 microservice화 시키도록 하겠습니다. 이전 글에서 구성했던 Kafka와 Zookeeper를 모두 포함하여 yml 파일을 작성하고 "docker compose up -d" 명령어를 실행하도록 하겠습니다. 이때 새로운 폴더에서 진행합니다.
| docker-compose.yml |
| version: '2' services: zookeeper-1: image: confluentinc/cp-zookeeper:latest hostname: zookeeper-1 ports: - "12181:12181" environment: ZOOKEEPER_SERVER_ID: 1 ZOOKEEPER_CLIENT_PORT: 12181 ZOOKEEPER_TICK_TIME: 2000 ZOOKEEPER_INIT_LIMIT: 5 ZOOKEEPER_SYNC_LIMIT: 2 ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888 zookeeper-2: image: confluentinc/cp-zookeeper:latest hostname: zookeeper-2 ports: - "22181:12181" environment: ZOOKEEPER_SERVER_ID: 2 ZOOKEEPER_CLIENT_PORT: 12181 ZOOKEEPER_TICK_TIME: 2000 ZOOKEEPER_INIT_LIMIT: 5 ZOOKEEPER_SYNC_LIMIT: 2 ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888 zookeeper-3: image: confluentinc/cp-zookeeper:latest hostname: zookeeper-3 ports: - "32181:12181" environment: ZOOKEEPER_SERVER_ID: 3 ZOOKEEPER_CLIENT_PORT: 12181 ZOOKEEPER_TICK_TIME: 2000 ZOOKEEPER_INIT_LIMIT: 5 ZOOKEEPER_SYNC_LIMIT: 2 ZOOKEEPER_SERVERS: zookeeper-1:12888:13888;zookeeper-2:22888:23888;zookeeper-3:32888:33888 kafka-1: image: confluentinc/cp-kafka:latest hostname: kafka-1 ports: - "19092:19092" depends_on: - zookeeper-1 - zookeeper-2 - zookeeper-3 environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-1:19092 kafka-2: image: confluentinc/cp-kafka:latest hostname: kafka-2 ports: - "29092:29092" depends_on: - zookeeper-1 - zookeeper-2 - zookeeper-3 environment: KAFKA_BROKER_ID: 2 KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-2:29092 kafka-3: image: confluentinc/cp-kafka:latest hostname: kafka-3 ports: - "39092:39092" depends_on: - zookeeper-1 - zookeeper-2 - zookeeper-3 environment: KAFKA_BROKER_ID: 3 KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:12181,zookeeper-2:12181,zookeeper-3:12181 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-3:39092 namenode: image: bde2020/hadoop-namenode:1.1.0-hadoop2.8-java8 container_name: namenode volumes: - ./data/namenode:/hadoop/dfs/name environment: - CLUSTER_NAME=test env_file: - ./hadoop.env ports: - 50070:50070 datanode: image: bde2020/hadoop-datanode:1.1.0-hadoop2.8-java8 depends_on: - namenode volumes: - ./data/datanode:/hadoop/dfs/data env_file: - ./hadoop.env ports: - 50075:50075 spark-master: image: bde2020/spark-master:2.1.0-hadoop2.8-hive-java8 container_name: spark-master ports: - 8080:8080 - 7077:7077 env_file: - ./hadoop.env spark-worker: image: bde2020/spark-worker:2.1.0-hadoop2.8-hive-java8 depends_on: - spark-master environment: - SPARK_MASTER=spark://spark-master:7077 ports: - 8081:8081 env_file: - ./hadoop.env spark-notebook: image: bde2020/spark-notebook:2.1.0-hadoop2.8-hive container_name: spark-notebook env_file: - ./hadoop.env ports: - 9001:9001 hue: image: bde2020/hdfs-filebrowser:3.11 ports: - 8088:8088 environment: - NAMENODE_HOST=namenode |
yml 파일을 모두 작성했다면 Hadoop 서비스에 필요한 volume mount를 위해 현재 폴더에 "data/namenode", "data/datanode" 폴더를 만듭니다. yml 파일에서 namenode와 datanode 서비스를 보면 이 폴더들을 대상으로 mount를 진행하기 때문입니다.
/* New Docker Compose folder */
$ mkdir -p data/namenode
$ mkdir -p data/datanode
그리고 마지막으로 hadoop.env 파일을 생성해줍니다. 파일의 내용은 아래와 같습니다.
CORE_CONF_fs_defaultFS=hdfs://namenode:8020
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031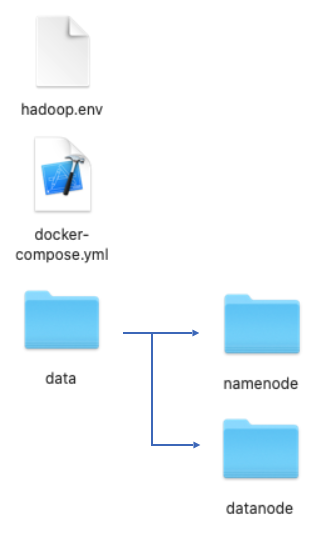
현재 폴더의 구조가 위와 같으면 준비가 완료된 상태입니다. 완료가 되었다면 Docker Compose 명령어를 실행해줍니다.
$ docker compose up -d정상적으로 실행되었다면 "docker compose ps" 명령어로 확인해줍니다.

Spark 실행하기
서비스들이 정상적으로 동작 중이라면 이제 우리들은 Spark 가 정상적으로 실행이 되고있는지 확인해야 합니다. 이때 Spark container에 접속해야 하는데 spark-master 또는 spark-worker 중 하나를 정하면 됩니다.
$ docker exec -it spark-master /bin/bash접속 후 "/spark/bin" 경로에 들어가면 여러가지 실행 파일들이 존재합니다. 저는 Spark 를 python으로 작성할 예정이기 때문에 pyspark를 실행해보겠습니다.
/* spark-master Terminal */
$ /spark/bin/pyspark정상적으로 실행되었다면 아래처럼 pyspark shell에 접속할 수 있습니다.

간단한 pyspark 예제 코드를 실행해보고 이번 글은 마무리하겠습니다. WordCount 예제를 실행하기 위해 test 파일을 생성합니다. 파일 내용은 원하는 것을 저장하시면 됩니다. ( vim을 쓴다면 설치해야 합니다 -> $ apt install -y vim )
$ pwd
/root
$ vim test
/* put "test" file to HDFS path */
$ hdfs dfs -put /root/test /아래의 코드를 pyspark shell에서 실행하면 결과를 확인할 수 있습니다.
# run this command in pyspark shell
text_file = sc.textFile("hdfs:///test")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs:///result")$ hdfs dfs -cat /result/*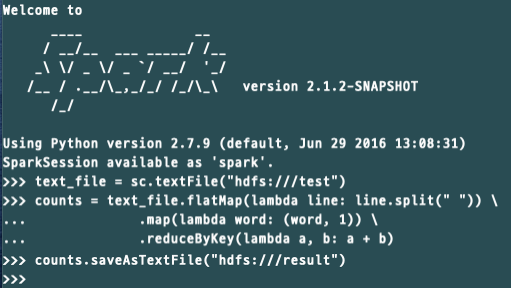

이제 Kafka, Spark , Hadoop 서비스가 모두 Docker Compose로 준비되었으니 다음 글에서는 Spark streaming을 이용하여 Kafka topic을 받아오는 방법에 대해 설명하도록 하겠습니다.
References
https://github.com/big-data-europe/docker-hadoop-spark-workbench