![[Hive] Complex Json 데이터 테이블 생성하기 (Json SerDe)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F70Zom%2FbtrTDYWqIIv%2FFMtlXXtkp0w18gq9nnuyR1%2Fimg.png)
Json 데이터를 사용하다보면 Json의 스키마 자체가 상당히 복잡하고 거대한 경우가 있습니다. 이번 글에서는 complex Json 데이터를 이용해 Hive 테이블을 생성하는 방법에 대해 소개하겠습니다.
Json 데이터로 Hive 테이블 만들기
Json 데이터로 Hive 테이블을 만드는 방법은 여러가지가 있겠지만 이번 글에서는 Json SerDe를 이용한 방법을 소개할 예정입니다. 우선 Json SerDe를 위한 jar 파일부터 아래 링크에서 다운받도록 하겠습니다.
Download dependencies for java class org.openx.data.jsonserde.JsonSerDe
io.starburst.openx.data json-serde 1.3.9-e.10 compile group: 'io.starburst.openx.data', name: 'json-serde', version: '1.3.9-e.10' //Thanks for using https://jar-download.com libraryDependencies += "io.starburst.openx.data" % "json-serde" % "1.3.9-e.10" //T
jar-download.com
위의 링크에서 1.3.7.3 버전을 다운 받고 zip 파일을 풀어주면 "json-1.3.7.3.jar", "json-serde-cdh5-shim-1.3.7.3.jar", "json-serde-1.3.7.3.jar" 파일들이 나오게 됩니다. 이 파일들을 Hive의 lib 디렉토리에 넣어줍니다.
저의 경우 Docker를 이용해서 Hive를 사용했고 "$HIVE_HOME/lib" 경로에 넣어줬습니다. ( $HIVE_HOME : /opt/hive ) HIVE_HOME은 사용하는 플랫폼마다 다를 수 있으니 참고바랍니다.
간단한 예제를 보여드리겠습니다. 아래처럼 Json 파일 생성 후 HDFS 경로에 넣어줍니다. ( 게시글에서는 이렇게 줄바꿈을 넣었지만, 개행문자는 뒤에서 Hive 테이블을 select 하는 과정에서 에러가 납니다. 꼭 줄바꿈을 모두 없애고 저장해주세요. )
| simple_schema.json |
| { "key1" : {"sub_key1" : "sub_value1", "sub_key2" : "sub_value2"}, "key2" : 1357, "key3" : ["list_value1", "list_value2", "list_value3"] } |
| {"key1" : {"sub_key1" : "sub_value1", "sub_key2" : "sub_value2"},"key2" : 1357,"key3" : ["list_value1", "list_value2", "list_value3"]} |
# HDFS에 테이블 폴더 만들기
$ hdfs dfs -mkdir /simple_schema_table_dir
# json 데이터 HDFS 경로에 넣기
$ hdfs dfs -put simple_schema.json /simple_schema_table_dir/
# 확인
$ hdfs dfs -ls /simple_schema_table_dir/
Found 1 items
-rw-r--r-- 3 root supergroup /simple_schema_table_dir/simple_schema.json
그럼 이제 이 테스트 데이터로 Hive 테이블을 만들어 보고 select 쿼리를 실행해보겠습니다.
# 테이블 생성
hive> create external table simple_schema_table(
> key1 struct<sub_key1:string, sub_key2:string>,
> key2 int,
> key3 array<string>
> )
> ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
> LOCATION 'hdfs://namenode:8020/simple_schema_table_dir';
OK
Time taken: 1.164 seconds
# Metadata 업데이트
hive> msck repair table simple_schema_table;
OK
Time taken: 0.109 seconds
# select * 쿼리 실행
hive> select * from simple_schema_table;
OK
{"sub_key1":"sub_value1","sub_key2":"sub_value2"} 1357 ["list_value1","list_value2","list_value3"]
Time taken: 2.216 seconds, Fetched: 1 row(s)
# Struct, Array select 쿼리 실행
hive> select key1.sub_key2, key3[1] from simple_schema_table;
OK
sub_value2 list_value2
Complex Json 데이터 create table 쿼리 자동 생성
하지만 아주 복잡하고 key 값만 총 100개 이상인 Json 데이터의 경우 어떻게 해야할까요? 위의 방법대로 하면 100 이상의 key 값들을 모두 명시하고 타입을 정의해줘야 합니다. 할수는 있지만 상당히 귀찮고, 시간이 많이 걸리기 때문에 할 엄두가 나지 않을 것입니다.
이러한 문제를 해결하기 위해 Json 스키마를 파악한 뒤 create table 쿼리까지 자동 생성해주는 오픈 소스가 있습니다. 아래 Github 링크에서 git clone을 통해 다운받아 주세요.
https://github.com/quux00/hive-json-schema
GitHub - quux00/hive-json-schema: Tool to generate a Hive schema from a JSON example doc
Tool to generate a Hive schema from a JSON example doc - GitHub - quux00/hive-json-schema: Tool to generate a Hive schema from a JSON example doc
github.com
사용법은 어렵지 않습니다. 해당 Github에 나와있는 것처럼 java 명령어를 이용해 바로 실행시켜줍니다.
$ java -cp target/json-hive-schema-1.0.jar net.thornydev.JsonHiveSchema simple_schema.json
위의 결과처럼 create table 쿼리문을 자동 생성하여 출력해줍니다. 위의 예시는 간단한 Json 스키마를 사용했지만, 제가 작업했던 게임 데이터를 저장한 Json 파일의 경우 상당히 complex 스키마임에도 불구하고 아래처럼 상당히 긴 쿼리를 만들어줍니다.
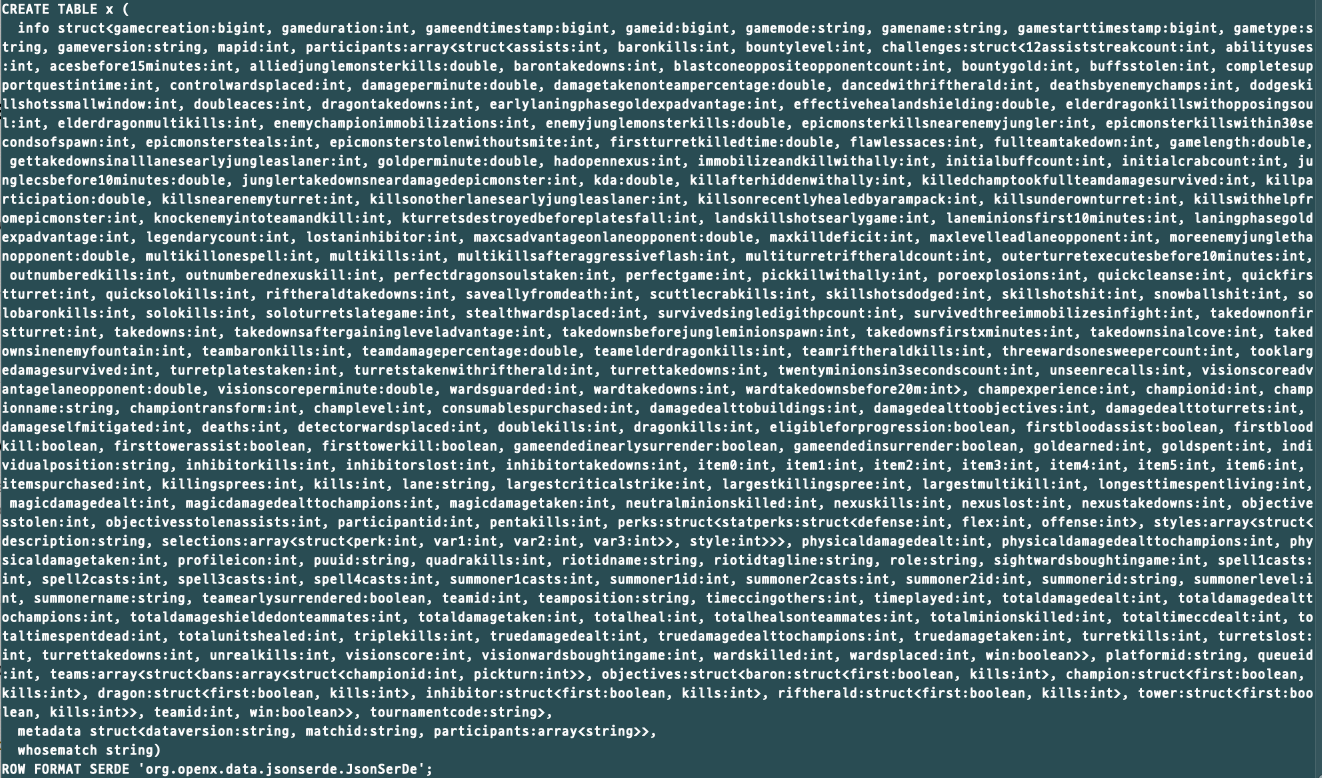
테이블 생성 쿼리문이 나왔다면 복사해서 Hive 쿼리로 실행해줍니다. Hive 쿼리가 정상적으로 실행되면, External 테이블의 경우 msck repair table 명령어로 Metadata 업데이트를 시켜주고 정상적으로 생성이 되었는지 위의 테스트 예시처럼 확인해줍니다.
'Hadoop Ecosystem > Hive' 카테고리의 다른 글
| [Hive] Compile 상세 과정 #2 - Optimization 종류와 소스 코드 분석 (2) | 2022.12.27 |
|---|---|
| [Hive] Compile 상세 과정 #1 - 쿼리 변화 과정과 형태 (0) | 2022.12.25 |
| [Hive] IntelliJ로 Runtime Debugging하기 (0) | 2022.11.12 |
| [Hive] limit 사용 시 leastNumRows 에러 발생 이슈 (0) | 2022.11.04 |
| [Hive] Metastore의 heap memory 증가 이슈 해결 과정 (2) | 2022.07.18 |