![[Hive] Compile 상세 과정 #2 - Optimization 종류와 소스 코드 분석](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDLjKw%2FbtrUGp6K1cA%2FAAAAAAAAAAAAAAAAAAAAAN7GEioVUdq7P7pcrYm-kML-UXMePvE5q9yneqaarbJN%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DW%252FxGY%252BIeZAYqFb7mNBHD6PjtFlc%253D)
이전 글에 이어서 Hive의 Compile 상세 과정 중 Optimization의 여러 종류와 Compile 과정의 소스 코드를 분석하도록 하겠습니다.
Hive Optimization 종류
Hive는 쿼리를 최종적인 Task Tree로 만들기까지의 Compile 과정에서 여러 종류의 Optimization을 수행합니다. 3가지 종류의 Optimization에 대해서 소개하도록 하겠습니다.
CBO (Cost-Based Optimization)
Semantic Analyzer가 AST를 OP Tree로 만드는 과정에서의 Optimization.
- 참고 링크 : https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
Cost-based optimization in Hive - Apache Hive - Apache Software Foundation
Abstract Apache Hadoop is a framework for the distributed processing of large data sets using clusters of computers typically composed of commodity hardware. Over last few years Apache Hadoop has become the de facto platform for distributed data processing
cwiki.apache.org
Apache Calcite를 이용하여 쿼리 구문을 Cost-Based Optimization하고 OP Tree를 생성합니다. 이때 Optimization은 뒤에서 나올 Logical Plan, Task Plan을 Optimization 하는 것과는 별개인 점을 참고 바랍니다.
Cost-Based Optimization 특징
- Join의 순서를 어떻게 정할지?
- 주어진 Join에 대해 어떤 알고리즘을 사용할지?
- Operator fail에 대하여 intermediate 결과를 계속 유지할지 또는 다시 계산할지?
- 병렬 작업의 정도
- Semi Join
| Apache Calcite? - SQL parsing, 쿼리 planning 등의 기능을 가지고 있는 오픈 소스 framework. - 적용하려는 SQL의 데이터나 metadata를 자체적으로 따로 저장하지 않음. - 그래서 외부 Metadata 또는 데이터를 plugin 방식으로 사용함. ( Hive에서 사용 시, Metastore가 이용됨. ) https://calcite.apache.org/ |
Logical Optimizaion
Logical Plan으로써 만들어진 OP Tree를 Optimization 수행 ( 실제 파일을 읽는 단계 X )
Logical Optimization 예시
- Predicate Pushdown : Table 전체 row를 scan 후 filter 하는 것이 아니라 filter 후 scan.
- Projection Pruning : Select 된 column에 대해서만 pruning.
- (Select - Select) 또는 (Filter-Filter) 구조를 하나의 Operator로 병합.
....
Physical Optimization
Physical Plan으로써 만들어진 Task Tree를 Optimization 수행 ( 실제 파일을 읽는 단계 )
Physical Optimization 예시
- Partition Pruning.
- Limit 절 사용 시, 일부 파일만 scan.
- Simple fetch 쿼리에 대해서는, MR 작업 없이 수행 ( hive.fetch.task.conversion )
....
Compile 과정 소스 코드 분석
Hive가 Compile을 하면서 쿼리가 변환되는 과정에 대해서 소스 코드와 함께 상세하게 알아보겠습니다.
( 아래 소스 코드들은 모두 Hive 2.3.2 버전입니다. )
0. Hive 쿼리
select * from test.tbl_1
where par=par_2
limit 7;
1. Hive 쿼리 -> AST
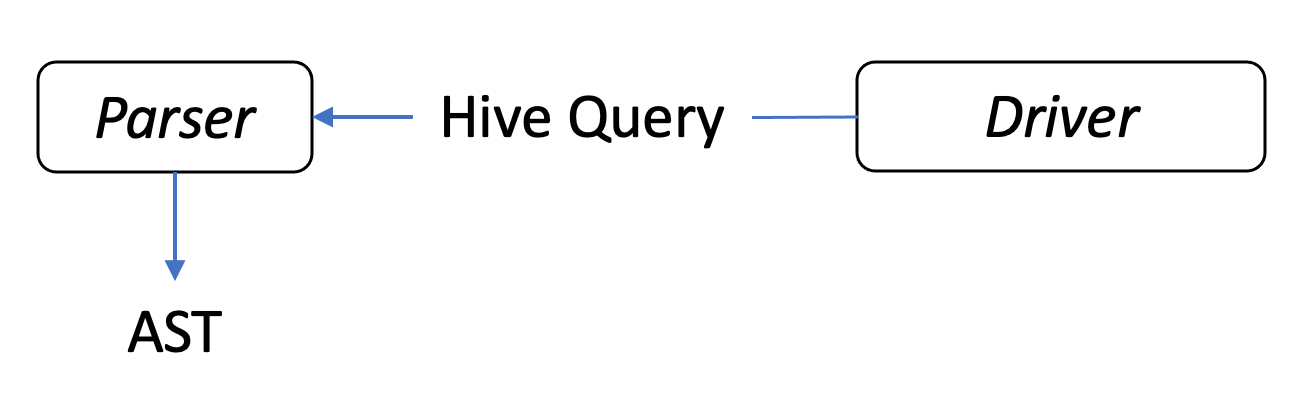
| Driver.java |
|
// compileInternal(String command, boolean deferClose) - Line:1317
ret = compile(command, true, deferClose);
...
// compile(String command, boolean resetTaskIds, boolean deferClose) - Line:468
ASTNode tree = ParseUtils.parse(command, ctx);
|
이전 글에서 언급한 것처럼 아키텍쳐 상으로는 Compiler라는 모듈이 존재하는 것처럼 보였지만, Line 1317 과 같이 실제 소스 코드에서는 Driver에서 compile() 메소드를 호출하는 것에 불과했습니다.
그리고 compile() 메소드에서 ParseUtils를 이용해 Hive 쿼리를 AST로 변환하는 것을 확인할 수 있고 결과물인 tree 변수는 아래처럼 쿼리가 각 토큰별로 트리 형태를 이루고 있습니다.
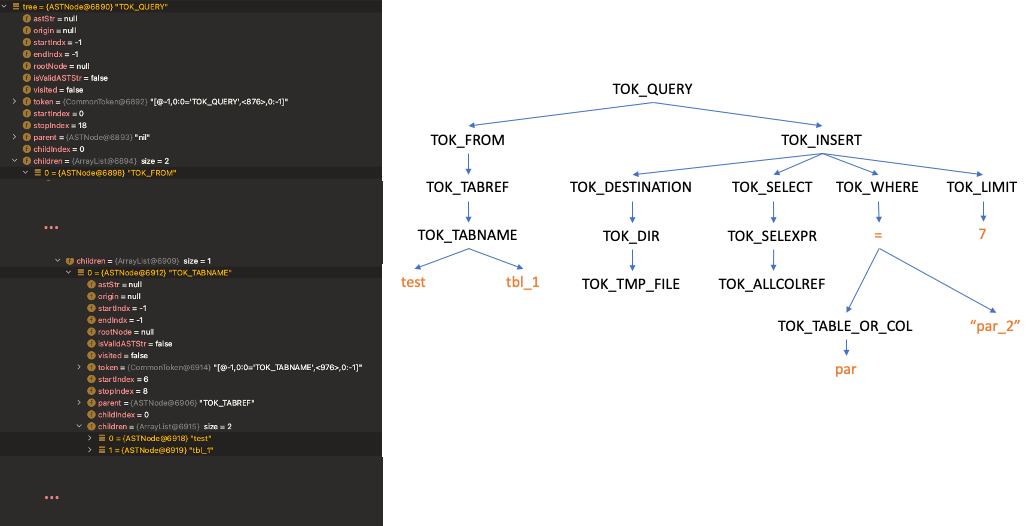
2. AST -> QB

| SemanticAnalyzerFactory.java |
|
// get(QueryState queryState, ASTNode tree) - Line:317
// hive.cbo.enabled 옵션 값에 따른 SemanticAnalyzer 객체 생성
// True : CalcitePlanner
// False : SemanticAnalyzer
SemanticAnalyzer semAnalyzer = HiveConf
.getBoolVar(queryState.getConf(), HiveConf.ConfVars.HIVE_CBO_ENABLED) ?
new CalcitePlanner(queryState) : new SemanticAnalyzer(queryState);
|
AST를 QB로 변환하기에 앞서 Driver에서 SemanticAnalyzer의 객체를 생성합니다. 그래서 SemanticAnalyzerFactory의 코드를 확인해보면 hive.cbo.enabled 옵션 값에 따라 CalcitePlanner 또는 SemanticAnalyzer로 할당하는 것을 확인할 수 있습니다. 즉, CalcitePlanner와 SemanticAnalyzer는 서로 상속 관계인 것을 확인할 수 있었습니다.
public class CalcitePlanner extends SemanticAnalyzer이후 다시 Driver에서 SemanticAnalyzer의 메소드를 호출합니다.
| Driver.java |
|
// compile(String command, boolean resetTaskIds, boolean deferClose) - Line:506
// Semantic Analyzer 함수 사용
sem.analyze(tree, ctx);
|
SenticAnalyzer의 메소드를 따라서 내부로 들어가면 doPhase1() 이라는 메소드에서 AST의 각 토큰 값을 DFS 탐색으로 순회하면서 QB 객체에 정보를 저장합니다. ( CalcitePlanner에 의해 QB가 생성되는 과정은 생략하겠습니다. )
| SemanticAnalyzer.java |
|
// doPhase1(ASTNode ast, QB qb, Phase1Ctx ctx_1, PlannerContext plannerCtx) - Line:1428
// AST의 각 토큰 값 DFS 순회로 QB에 정보 저장
skipRecursion = true;
switch (ast.getToken().getType()) {
case HiveParser.TOK_SELECTDI:
qb.countSelDi();
// fall through
case HiveParser.TOK_SELECT:
qb.countSel();
qbp.setSelExprForClause(ctx_1.dest, ast);
...
if (!skipRecursion) {
// Iterate over the rest of the children
int child_count = ast.getChildCount();
for (int child_pos = 0; child_pos < child_count && phase1Result; ++child_pos) {
// Recurse
phase1Result = phase1Result && doPhase1(
(ASTNode)ast.getChild(child_pos), qb, ctx_1, plannerCtx);
}
}
...
|
작업이 다 수행되면 아래와 같이 QB에 QBParseInfo와 QBMetaData에 필요한 정보가 저장됩니다.

3. QB -> OP Tree (Optimized)
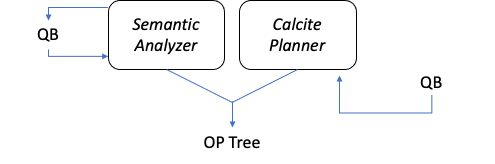
| SemanticAnalyzer.java |
|
// analyzeInternal(ASTNode ast, PlannerContext plannerCtx) - Line:11138
Operator sinkOp = genOPTree(ast, plannerCtx);
|
다시 SemanticAnalyzer에서 OP Tree를 생성하는 메소드를 호출합니다. 이때 CBO 옵션이 True라면 CalcitePlanner의 Override 된 genOPTree() 메소드가 호출되고, False라면 그대로 SemanticAnalyzer의 genOPTree() 메소드가 호출됩니다.

이후에는 SemanticAnalyzer에서 Optimizer 객체를 생성 후 OP Tree를 최적화합니다. 그 결과는 pCtx 변수에 저장되고 내부 변수들을 확인해보면 최적화된 OP Tree를 확인할 수 있습니다.
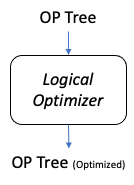
| SemanticAnalyzer.java |
|
// analyzeInternal(ASTNode ast, PlannerContext plannerCtx) - Line:11244
Optimizer optm = new Optimizer();
optm.setPctx(pCtx);
optm.initialize(conf);
pCtx = optm.optimize();
|

5. OP Tree (Optimized) -> Task Tree (Optimized)
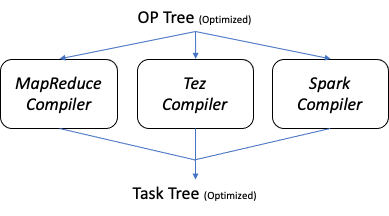
| TezCompilerFactory.java |
|
// TaskCompiler getCompiler(HiveConf conf, ParseContext parseContext) - Line:39
// Execution Engine에 따른 Compiler 객체 생성
if (HiveConf.getVar(conf, HiveConf.ConfVars.HIVE_EXECUTION_ENGINE).equals("tez")) {
return new TezCompiler();
} else if (HiveConf.getVar(conf, HiveConf.ConfVars.HIVE_EXECUTION_ENGINE).equals("spark")) {
return new SparkCompiler();
} else {
return new MapReduceCompiler();
}
|
TaskCompiler는 Hive의 Execution Engine 종류에 따라 객체가 생성됩니다.
| SemanticAnalyzer.java |
|
// analyzeInternal(ASTNode ast, PlannerContext plannerCtx) - Line:11273
compiler.compile(pCtx, rootTasks, inputs, outputs);
|
SemanticAnalyzer에서 TaskCompiler를 이용하여 Task Tree를 생성합니다. 이때 TaskCompiler의 compile 메소드는 Task Tree 생성 및 최적화 과정을 모두 포함합니다.
| TaskCompiler.java |
|
// compile(final ParseContext pCtx, final List<Task<? extends Serializable>> rootTasks,
// final HashSet<ReadEntity> inputs, final HashSet<WriteEntity> outputs) - Line:279
generateTaskTree(rootTasks, pCtx, mvTask, inputs, outputs);
// compile(final ParseContext pCtx, final List<Task<? extends Serializable>> rootTasks,
// final HashSet<ReadEntity> inputs, final HashSet<WriteEntity> outputs) - Line:292
optimizeTaskPlan(rootTasks, pCtx, ctx);
|
최적화까지 모두 수행되면 아래와 같이 rootTasks와 fetchTask에 Task들이 부여됩니다.
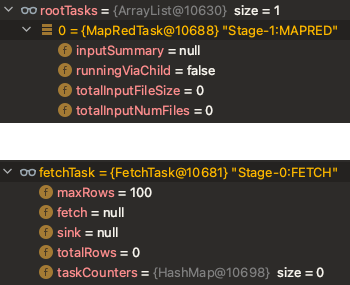
위의 과정으로 Compile 과정은 모두 종료가 됩니다. 마지막으로 Driver는 Execution Engine에 Task들을 전달하면서 YARN을 통해 어플리케이션이 실행됩니다.
Hive 쿼리 실행 Log 내용 이해하기
이제는 위의 내용들을 기반으로 Hive 쿼리를 실행할 때 출력되는 Log를 이해할 수 있을 것입니다. ( Debug 모드 출력 )
| Debug_Console.log |
|
// Hive 쿼리
> select * from test.tbl_1 where par="par_2" limit 7; // Parser : Hive 쿼리 -> AST 22/12/27 08:22:44 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.ParseDriver: Parsing command: select * from test.tbl_1 where par="par_2" limit 7
22/12/27 08:22:44 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.ParseDriver: Parse Completed
// Semantic Analyzer ( Calcite Planner ) 22/12/27 08:22:45 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO parse.CalcitePlanner: Starting Semantic Analysis
22/12/27 08:22:47 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.CalcitePlanner: CBO Planning details:
22/12/27 08:22:47 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.CalcitePlanner: Original Plan:
HiveSortLimit(offset=[0], fetch=[7])
HiveProject(col_1=[$0], col_2=[$1], col_3=[$2], par=[$3])
HiveFilter(condition=[=($3, _UTF-16LE'par_2')])
HiveTableScan(table=[[test.tbl_1]], table:alias=[tbl_1])
22/12/27 08:22:47 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.CalcitePlanner: Plan After Join Reordering:
HiveSortLimit(fetch=[7]): rowcount = 1.0, cumulative cost = {0.0 rows, 0.0 cpu, 0.0 io}, id = 121
HiveProject(col_1=[$0], col_2=[$1], col_3=[$2], par=[CAST(_UTF-16LE'par_2'):VARCHAR(2147483647) CHARACTER SET "UTF-16LE" COLLATE "ISO-8859-1$en_US$primary"]): rowcount = 1.0, cumulative cost = {0.0 rows, 0.0 cpu, 0.0 io}, id = 119
HiveFilter(condition=[=($3, _UTF-16LE'par_2')]): rowcount = 1.0, cumulative cost = {0.0 rows, 0.0 cpu, 0.0 io}, id = 117
HiveTableScan(table=[[test.tbl_1]], table:alias=[tbl_1]): rowcount = 1.0, cumulative cost = {0}, id = 67
22/12/27 08:22:47 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO parse.CalcitePlanner: CBO Succeeded; optimized logical plan.
// OP Tree 22/12/27 08:22:47 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.CalcitePlanner: Before logical optimization TS[0]-FIL[1]-SEL[2]-LIM[3]-FS[4]
// OP Tree (Optimized) 22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG parse.CalcitePlanner: After logical optimization
TS[0]-SEL[2]-LIM[3]-LIST_SINK[6]
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO ql.Driver: Semantic Analysis Completed
// Task Tree 22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO exec.TableScanOperator: Initializing operator TS[0]
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO exec.SelectOperator: Initializing operator SEL[2]
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO exec.LimitOperator: Initializing operator LIM[3]
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: INFO exec.ListSinkOperator: Initializing operator LIST_SINK[6]
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG exec.ListSinkOperator: Initialization Done 6 LIST_SINK done is reset.
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG exec.LimitOperator: Initialization Done 3 LIM done is reset.
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG exec.SelectOperator: Initialization Done 2 SEL done is reset.
22/12/27 08:22:48 [3852e623-31d5-427e-908a-5b621396c939 main]: DEBUG exec.TableScanOperator: Initialization Done 0 TS done is reset.
// Result 1 banana 5 par_2
2 apple 34 par_2
3 melon 156 par_2
4 lemon 23 par_2
5 tomato 11 par_2
6 banana 41 par_2
7 apple 52 par_2
Time taken: 3.81 seconds, Fetched: 7 row(s)
|
'Hadoop Ecosystem > Hive' 카테고리의 다른 글
| [Hive] Compile 상세 과정 #1 - 쿼리 변화 과정과 형태 (0) | 2022.12.25 |
|---|---|
| [Hive] Complex Json 데이터 테이블 생성하기 (Json SerDe) (0) | 2022.12.15 |
| [Hive] IntelliJ로 Runtime Debugging하기 (0) | 2022.11.12 |
| [Hive] limit 사용 시 leastNumRows 에러 발생 이슈 (0) | 2022.11.04 |
| [Hive] Metastore의 heap memory 증가 이슈 해결 과정 (2) | 2022.07.18 |