
지난 글에서 Spring을 통해 Match 정보를 Kafka에 전송하는 과정까지 진행했습니다. 이번 글에서는 Kafka에 쌓인 데이터 확인과 Spark Streaming으로 Kafka Consumer를 구현하는 과정을 진행하겠습니다.
Kafka Topic 확인하기
Kafka Manager를 이용하면 Kafka 클러스터와 Topic 모니터링을 효율적으로 할 수 있습니다. Kafka 서비스를 위한 docker compose의 Kafka Manager 웹 GUI를 보면 아래와 같습니다. ( Kafka Cluster 등록 과정 필요 )
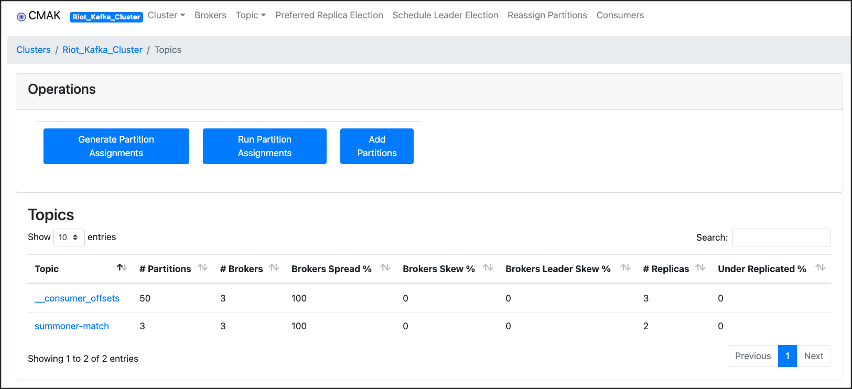
Topic 정보 또한 확인이 가능합니다. GUI가 없다면 직접 터미널에서 명령어를 통해 확인해야만 합니다. 하지만 Kafka Manager를 통해 쉽게 정보들을 확인할 수 있습니다. Spring에서 "summoner-match"라는 이름의 Topic 데이터가 Kafka Broker에 저장되어 있는 모습을 볼 수 있습니다.
Spark Streaming으로 Consumer 구현
Spark Streaming을 이용하여 Kafka Topic을 가져오는 것은 지난 글들에서 진행했습니다. ( [Spark] Spark structured streaming으로 Kafka topic 받기 #3 - pyspark로 HDFS에 topic data 저장하기) 이번에도 이와 비슷하게 진행했고, Json 데이터를 다룬다는 점에서 차이가 있었습니다.
Spark를 사용하기 위한 docker-compose.yml 파일은 아래처럼 명시해줍니다. HDFS 또는 Hive와 같은 서비스가 추가적인 서비스가 필요하다면 이어서 추가해주면 됩니다.
| docker-compose.yml |
|
version: '2'
services:
spark-master:
image: bde2020/spark-master:2.4.0-hadoop2.8
ports:
- "8080:8080"
- "7077:7077"
env_file:
- ./hadoop.env
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:2.4.0-hadoop2.8
depends_on:
- spark-master
ports:
- "8081:8081"
env_file:
- ./hadoop.env
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-notebook:
image: bde2020/spark-notebook:2.1.0-hadoop2.8-hive
container_name: spark-notebook
env_file:
- ./hadoop.env
ports:
- 9001:9001
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.8-java8
container_name: namenode
volumes:
- ./data/namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- 50070:50070
datanode:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.8-java8
depends_on:
- namenode
volumes:
- ./data/datanode:/hadoop/dfs/data
env_file:
- ./hadoop.env
ports:
- 50075:50075
hive-server:
image: bde2020/hive:2.3.2-postgresql-metastore
volumes:
- ./hive_dir:/root
env_file:
- ./hadoop.env
environment:
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
SERVICE_PRECONDITION: "hive-metastore:9083"
ports:
- "10000:10000"
- "8000:8000"
hive-metastore:
image: bde2020/hive:2.3.2-postgresql-metastore
env_file:
- ./hadoop.env
command: /opt/hive/bin/hive --service metastore
environment:
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
ports:
- "9083:9083"
hive-metastore-postgresql:
image: bde2020/hive-metastore-postgresql:2.3.0
|
Spark에서 Match 데이터를 Kafka로부터 가져와 전처리 후 필요한 정보만 선별하여 HDFS에 저장하고 싶었습니다. 하지만 데이터를 사용하기 위한 방법으로, 원본 데이터를 데이터 플랫폼에 저장 후 파싱 후 새로운 테이블로 저장하는 데이터 마트 구축 방식을 이용하고 싶었습니다. 그래서 Kafka Topic을 json 데이터 형태로 HDFS에 저장하는 것을 목표로 정했습니다.
Spark Streaming으로 Consumer를 구현한 코드와 spark-submit 실행 코드는 아래와 같습니다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
import json
spark = SparkSession.builder \
.master("local") \
.appName("Consume Riot Data") \
.getOrCreate()
spark.sparkContext.setLogLevel('ERROR')
json_schema = spark.read.json("/riot/sample_one_data").schema
# Read stream
log = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "host.docker.internal:19096,host.docker.internal:29096,host.docker.internal:39096") \
.option("subscribe", "summoner-match") \
.option("startingOffsets", "earliest") \
.load()
print("**ReadStream Kafka topic schema")
log.printSchema()
parsed_df = log.select(from_json(col("value").cast("string"), json_schema) \
.alias("parsed_value")).select(col("parsed_value.*"))
query = parsed_df \
.writeStream \
.format("json") \
.option("checkpointLocation", "/checkpoints/match_raw_data") \
.option("path", "/riot/match_raw_data") \
.option("maxRecordsPerFile", 1) \
.start()
query2 = parsed_df \
.writeStream \
.format("console") \
.start()
query.awaitTermination()
query2.awaitTermination()$ sh /spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 consume_match_data_store.py
이때 spark.readStream에서 Kafka 주소에 "host.docker.internal:19096 ... 29096 ... 39096"을 넣어준 이유는 Kafka 클러스터와 Spark 서비스가 실행되는 클러스터는 서로 다른 docker compose이므로 서로의 hostname을 인식할 수 없기 때문입니다.
Kafka와 Spark의 docker-compose와 서로 통신하는 구조는 아래와 같습니다. Kafka를 docker로 사용할 때 host machine과 통신하는 구체적인 방법은 이전 글을 참고해주시기 바랍니다.
[Kafka] Docker로 Kafka 구성 시 Host machine과 통신하기 위한 listener 설정 방법

Match 데이터 HDFS에 저장된 결과
위의 Spark Streaming을 통한 Consumer 작업이 끝났다면, HDFS 명령어를 통해 데이터가 제대로 저장되었는지 확인합니다.
$ hdfs dfs -ls /riot/match_raw_data
이렇게 저장된 데이터를 Hive 테이블에 적재하는 과정은 다음 글에서 소개하도록 하겠습니다.