
Riot 데이터를 수집해서 최종적으로 HDFS에 저장하는 과정까지 성공했습니다( 비록 미흡한 점이 상당히 많지만.... ). 이제는 저장된 데이터를 기반으로 Hive 테이블을 생성하는 과정을 진행하겠습니다.
Docker Compose에 Hive 서비스 추가
Kafka에 있는 데이터를 HDFS에 저장하기 위해 Docker Compose에 Spark와 HDFS 서비스들을 추가했었습니다. 이번에는 동일한 Docker Compose에 Hive 서비스를 추가하겠습니다.
| docker-compose.yml |
|
version: '2'
services:
spark-master:
image: bde2020/spark-master:2.4.0-hadoop2.8
ports:
- "8080:8080"
- "7077:7077"
env_file:
- ./hadoop.env
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:2.4.0-hadoop2.8
depends_on:
- spark-master
ports:
- "8081:8081"
env_file:
- ./hadoop.env
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-notebook:
image: bde2020/spark-notebook:2.1.0-hadoop2.8-hive
container_name: spark-notebook
env_file:
- ./hadoop.env
ports:
- 9001:9001
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.8-java8
container_name: namenode
volumes:
- ./data/namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- 50070:50070
datanode:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.8-java8
depends_on:
- namenode
volumes:
- ./data/datanode:/hadoop/dfs/data
env_file:
- ./hadoop.env
ports:
- 50075:50075
hive-server:
image: bde2020/hive:2.3.2-postgresql-metastore
volumes:
- ./hive_dir:/root
env_file:
- ./hadoop.env
environment:
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
SERVICE_PRECONDITION: "hive-metastore:9083"
ports:
- "10000:10000"
- "8000:8000"
hive-metastore:
image: bde2020/hive:2.3.2-postgresql-metastore
env_file:
- ./hadoop.env
command: /opt/hive/bin/hive --service metastore
environment:
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
ports:
- "9083:9083"
hive-metastore-postgresql:
image: bde2020/hive-metastore-postgresql:2.3.0
|
Match 데이터 경로 수정
이전 글에서 Match 데이터를 저장한 HDFS 경로는 "/riot/match_raw_data" 였습니다. 하지만 데이터가 계속해서 쌓이면서 성능의 이슈를 생각한다면 Hive 테이블의 partition이 필요할 것입니다. 그래서 닉네임을 기준으로 partition을 구분하겠습니다.
만약 닉네임이 "aaa"라면 경로는 "/riot/match_raw_data/name=aaa"가 될 것입니다. 해당 파티션으로 데이터를 옮긴 후 결과는 아래와 같습니다.
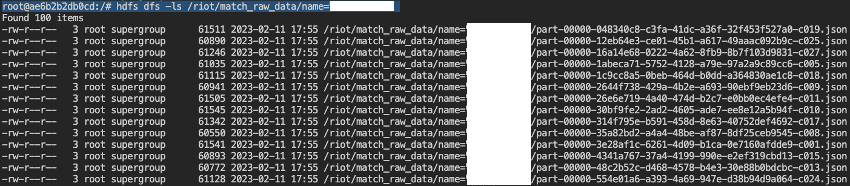
Match 데이터 Hive 테이블 생성
데이터는 모두 준비되었으니 이제 테이블을 생성하겠습니다. Hive 테이블 생성 시 Json 파일을 기반으로 한다면 JsonSerDe 형식으로 지정할 수 있습니다. 하지만 문제는 따로 있습니다. Riot Match 데이터의 경우 모든 키 값의 갯수가 약 300개 이상입니다. 테이블 생성 쿼리를 사용할 때 Json 구조에 맞는 column 명시가 필수적입니다. 300개 이상의 column 값들을 모두 적는 것은 상당히 어렵고 시간 낭비라고 생각합니다.
이러한 문제를 해결한 내용이 있으니 이 글을 참고하시기 바랍니다.
[Hive] Complex Json 데이터 테이블 생성하기 (Json SerDe)
[Hive] Complex Json 데이터 테이블 생성하기 (Json SerDe)
Json 데이터를 사용하다보면 Json의 스키마 자체가 상당히 복잡하고 거대한 경우가 있습니다. 이번 글에서는 complex Json 데이터를 이용해 Hive 테이블을 생성하는 방법에 대해 소개하겠습니다. Json
taaewoo.tistory.com
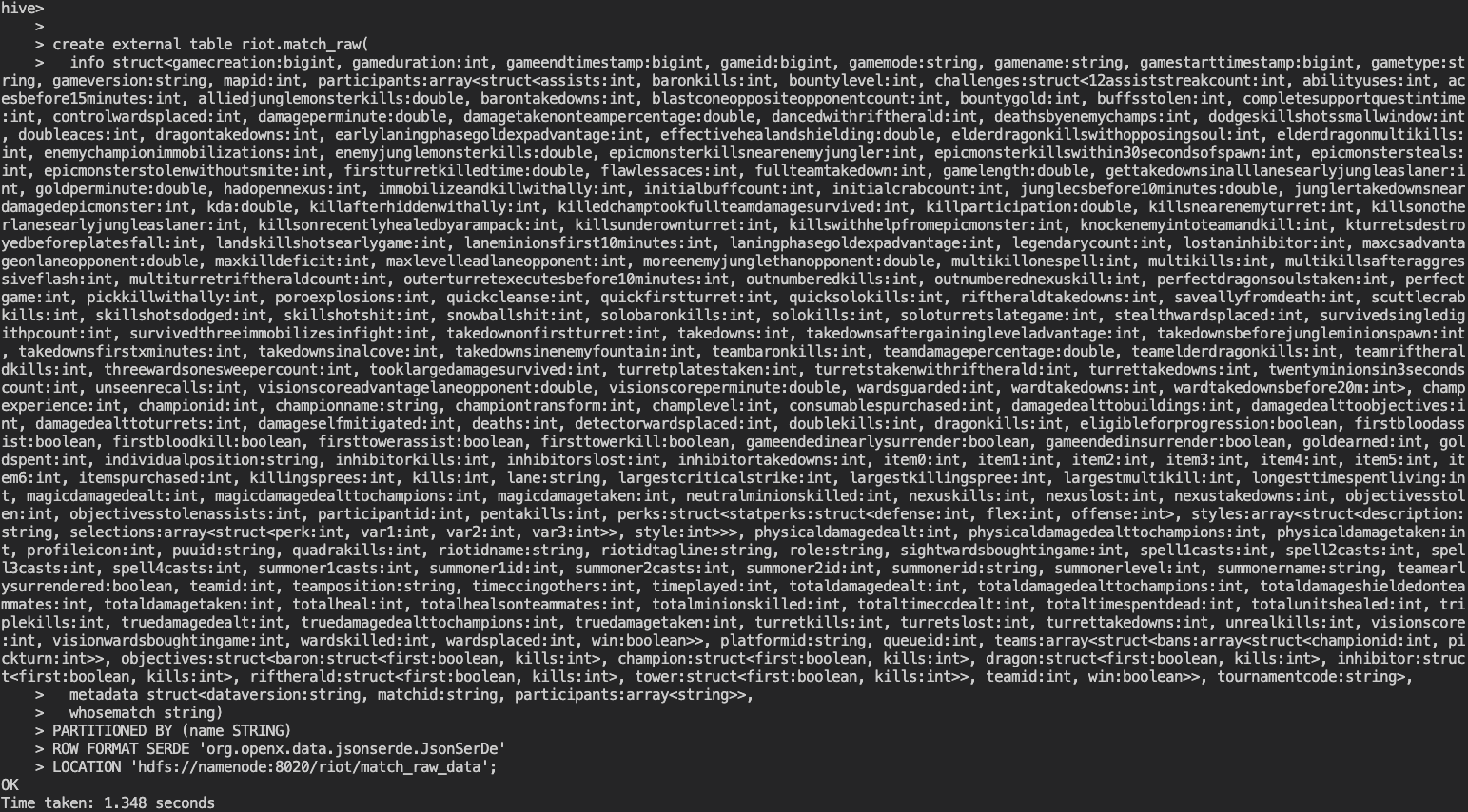
위의 글을 참고해 Hive 테이블 생성 쿼리를 자동으로 추출하면 아래와 같습니다. Partition과 해당 파일의 Location 값을 추가로 적었습니다. Column은 실제로 3개밖에 없지만 아주 복잡한 Json 구조입니다.
create external table riot.match_raw(
info struct<gamecreation:bigint, gameduration:int, gameendtimestamp:bigint, gameid:bigint, ...
metadata struct<dataversion:string, matchid:string, participants:array<string>>,
whosematch string)
PARTITIONED BY (name STRING)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 'hdfs://namenode:8020/riot/match_raw_data';
쿼리를 실행했을 때 정상적으로 수행된 것을 확인할 수 있습니다.
msck repair 명령어로 데이터 동기화 후 테이블을 조회해보면 아래와 같습니다. Json 구조가 워낙 복잡해 파악하기 어렵지만 확대하시면 더 자세하게 볼 수 있습니다.


다음 글에서는 이 데이터를 활용하는 과정에 대해 소개하도록 하겠습니다.